Introduction
Header2
bla bla
Header3
bla bla

مشاهدات، تجربیات و داستان های دواپس از زبان ما و شما
bla bla
bla bla

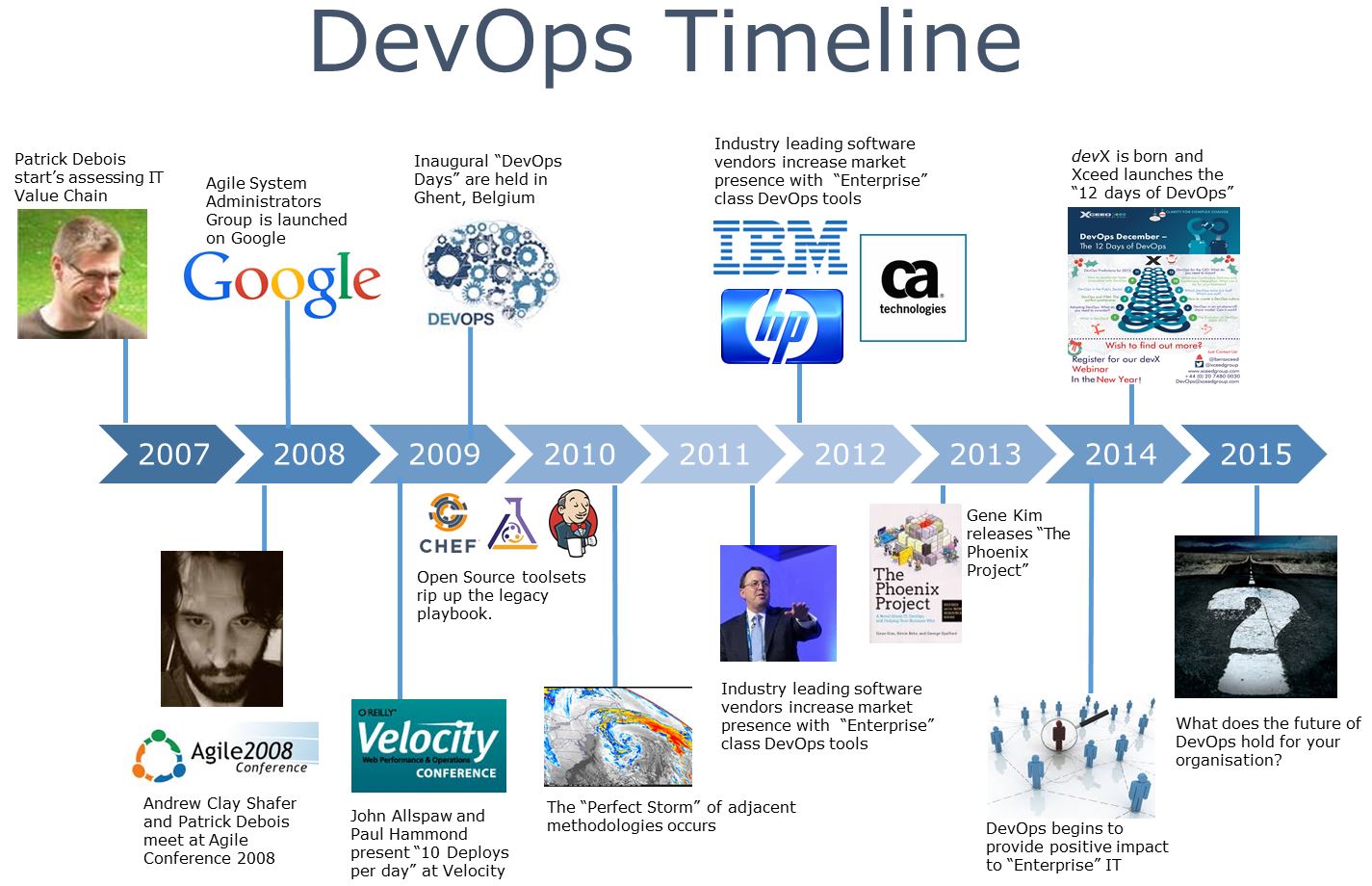
سال 2007 میلادی آقای پاتریک دبوآ (Patrick Debois) درگیر پروژه ی جایی دیتاسنتر دولت بلژیک شد و با یک چالش مواجه شد: سیستم ادمین ها و توسعه دهندگان در تعامل با هم به مشکلاتی برمیخوردند که تاثیر منفی در روند اجرای کار داشت.
آگوست 2008 در کنفرانس سالانه چابک که در تورنتو کانادا برگزار شد(Agile 2008 Conference)، آقای اندرو شفر (Andrew Shafer) پیشنهاد نشستی با عنوان زیرساخت چابک (Agile Infrastructure) را می دهد که تقریبا با استفبال هیچکسی مواجه نمی شود به جز یک نفر و آن یک نفر کسی نبود به جز Patrick Debois ! به دلیل استقبال کمی که صورت گرفت، Andrew از برگزاری اون نشست صرف نظر میکنه. بعد از آن Patrick به دنبال Andrew در یک گفتگوی سرپایی راجع به این موضوع صحبت می کنند و گروه Agile System Administration را در google group ایجاد می کنند.
ژون 2009 در کنفرانس O’Reilly Velocity 2009، آقایان John Allspaw و Paul Hammond سخنرانی معروفی تحت عنوان “10 استقرار در روز: نتیجه همکاری توسعه و عملیات در فلیکر” داشتند. پاتریک که از راه دور این کنفرانس را تماشای می کرد، در توییتر ابراز تاسف کرد که نتوانسته به صورت حضوری شرکت کند. Paul Nasrat در پاسخ به این توییت پیشنهاد برگزاری کنفرانس در بلژیک را به Patrick Debois می دهد.
10 Deploys Per Day: Dev and Ops Cooperation at Flickr from John Allspaw
اکتبر 2009 Patrik به توصیه John عمل کرد و به فکر برگزاری یک کنفرانس در بلژیک افتاد. اول از همه باید یک اسم مناسب برای این کنفرانس انتخال می کرد. سه حرف Development و سه حرف از Operations به اضافه کلمه days چیزی بود که نام این کنفرانس را تشکیل داد “DevOpsDays”. این کنفرانس در 30 اکتبر با مجموعه قابل توجهی از توسعه دهندگان، sys admin ها، متخصصان ابزار و سایر افراد تشکیل شد. بعد از پایان کنفرانس مباحث در توییتر ادامه پیدا کرد. Patrik به هشتگ #DevOps را برای ادامه بحث انتخاب کرد تا خلاصه تر و راحت تر باشد. از آن زمان تا به حال، این جنبش را به نام DevOps (دوآپس) می شناسیم. (در نحوه نوشتن کلمه دوآپس توافق جامعی وجود ندارد و هر سه حالت DevOps و Devops و devops استفاده می شود)
آوریل 2012 Patrik Debois در یک مصاحبه ویدیویی در سال 2012 اذغان کرد که نامگذاری این جنبش به اندازه ای که به نظر می رسد خیلی عمدی نبوده. (به نظر میرسه منظور اینه که خیلی دقیق و فکر شده نیست). در ادامه Patrik میگوید: “من به این دلیل اسم DevOpsDays را در راستای همکاری تیم های توسعه و عملیات انتخاب کردم که اسم “Agile System Administration” طولانی بود و هیچ وقت برنامه ی بزرگی برای دنیایی به نام DevOps وجود نداشته.
سال 2013 موسسه Puppet Labs اولین نظرسنجی وضعیت دوآپس (State of DevOps) را برگزار کرد تا یک ارزیابی ای از روند رشد و عملکرد این حوزه به دست بیاید.
ممنون که ما را دنبال می کنید.
هدف مشترک هر کسب و کار، موفقیت تجاری است. تولید محصولات یا خدمات عالی که مشتری عاشق آن بشود منجر به درآمدزایی و سودآوری می شود. در سازمانی که افراد و دپارتمان های مختلف آن به درستی با یکدیگر تعامل ندارند، هزینه های سربار کارها زیاد شده و در نهایت به کسب و کار لطمه می زند.
اتهام به دیگر واحد ها و نادیده گرفتن چالش هایی که با آن درگیر هستند، یه هیچ وجه سازنده و مفید نیست. اگر افراد و تیم ها تعامل سازنده ای با هم نداشته باشند، فاصله ی بین آن ها به مرور بیشتر می شود و این به معنی تحمیل خسارت و زیان به سازمان و کسب و کار است.
در شرایطی که فشار سهامداران برای افزایش کیفیت و پایداری محصولات و کوتاه تر کردن زمان تولید و ارائه به بازار بیشتر از همیشه شده است، اهمیت برقراری ارتباط با یک زبان مشترک بین تیم ها و افراد بیشتر از همیشه شده است.
اگر شما یک مدیر یا کارشناس IT هستید و در حال حاضر از مزایای دواپس بهره نمی برید، توصیه من این است که در رویکرد خود یک بازنگری کلی داشته باشید، در ادامه علت این توصیه را توضیح خواهم داد …
در مطالب قبلی راجع به مفهوم DevOps صحبت کردیم (اینجا و اینجا). همچنین راجع به چارچوب CALMS در دواپس نوشتیم و در جایی دیگر راجع به کج فهمی هایی که در باره DevOps وجود دارد صحبت شد. در ادامه ی این سری مطالب قصد داریم راجع به اهمیت دواپس و مزایای دواپس بنویسیم. لطفا با ما همراه باشید.
![[عکس همکاری]](http://hidevops.com/wp-content/uploads/2018/04/collaboration.jpg)
هر شخص یا هر تیم مستقل، چه توسعه دهنده باشد، چه تیم عملیات، تضمین کیفیت یا تیم پشتیبانی، روزانه با چالش هایی مواجه می شوند. این چالش ها بر کسب و کار تاثیر گزارند، و حادثه ای در یک بخش می تواند در سایر بخش ها طنین انداز شود.
فارغ از اینکه چه کسی مسوول و پاسخگوی آن است، اما مشکل باید برطرف شود. سرزنش و گرفتن انگشت اشاره به سمت دیگران کمکی به حل مشکل نمی کند، و باید از زمان و منابع موجود برای حل مشکل کمال استفاده را کرد. بدون همکاری، فرایند حل مشکل طولانی تر می شود و می تواند منجر به پیدایش مشکلات دیگری هم شود که بلافاصله نمایان نمی شود.
همکاری با یکدیگر در سایه ی ارتباط موثر به شما اجازه می دهد که راه کارهایی را ایجاد کنید که بتواند از حادثه های مشابه در آینده جلوگیری کند.

با بهبود سرعت رسیدن به بازار می توانید مزیت رقابتی در بازاری را بدست آورید که نرم افزارها در آن عمر کمی دارند و خیلی زود به زود کهنه می شوند.
معرفی یک راهکار DevOps شما را قادر می سازد تا در یک دوره زمانی کوتاهتر از روش سنتی از یک مفهوم اولیه به یک محصول قابل قبول برسید. همچنین شما فرصت خواهید داشت منابع را زودتر آزاد کنید و بر بهبود نرم افزار و زیرساخت ها تمرکز کنید. به این معنی که شما با تحویل سریعتر ویژگی ها و قابلیت های جدید نرم افزاری می توانید رقبای خود را پشت سر بگزارید.

یکپارچه سازی مستمر فرایندی است که در آن توسعه دهندگان می توانند به طور مستمر کارهای خود را با هم یکپارچه کنند. (اطلاعات بیشتر: Continuous Integration). استفاده از یک فرایند بیلد اتوماتیک به همراه اجرای تست های اتوماتیک، ما را قادر می سازد که با هر تغییر در کد، از تاثیرات منفی احتمالی آن تغییر بر کل نرم افزار مطلع شویم.
تحویل مستمر رویکردی در مهندسی نرم افزار است که تیم ها را قادر می سازد نرم افزار تولید شده را به روشی سریع و مطمئن برای انتشار و تحویل آماده کنند. این فرایند از لحظه اضافه شدن یا تغییر کد در source control شروع می شود و شامل بیلد، تست، پیکربندی و انتشار می شود. (اطلاعات بیشتر: Continuous Delivery).
فرایند های CI و CD توسعه دهندگان را قادر می سازد تا مشکلات را هر چه سریعتر شناسایی و رفع کنند. شناسایی سریع مشکلات به معنی پیچیدگی کمتر و نیاز به کار کمتر برای رفع آن و فرایند دیباگ است. از ابزارهای رایجی که برای انجام عملیات CI و CD وجود دارند می توان به Jenkins، Team City و TFS یا Team Foundation Server اشاره کرد.
بنا به گزارش سالانه Puppet Labs در سال 2014، سازمان های فناوری اطلاعات با کارایی بالا که از روش های DevOps استفاده می کنند، بسیار چابک تر و قابل اطمینان تر از رقیبان خود هستند. گزارش سال 2015 همین موسسه نشان می دهد که روش های دوآپس و فرهنگ دوآپس سازمان ها را قادر می کند که بتوانند اپلیکیشن های خود را 30 برابر بیشتر منتشر کنند، همچنین زمان اعمال یک تغییر یا رفع یک مشکل 200 برابر سریعتر از سایر سازمان ها باشد. در چنین سازمانی بهره وری و تولید محصولات بهتر نرم افزاری، بارها بیشتر از سایر سازمان ها است.
ارزش این ابزارها و روش ها نه تنها در کسب و کار و کارایی محصولات است، بلکه تاثیر مثبتی در روحیه کارکنان آن سازمان دارد. در چنین شرایطی علاوه بر راحت تر شدن کارهای تکراری و خسته کننده، اجازه بروز خلاقیت های فردی نیز بیشتر خواهد شد.

به طور سنتی، نگهداری از سرورها و سخت افزارها و محیط های عملیاتی، بر عهده ی تیم IT Operation (عملیات) و افرادی که آن ها را با نام System Administrators می شناسیم بوده است.
کار کردن به عنوان یک تیم واحد با اعضای چند-عملکردی (cross-functional) شامل مدیران پایگاه داده (DBAs)، تحلیلگران کسب و کار، توسعه دهندگان، تضمین کنندگان کیفیت، و مهندسان عملیاتی و مهندسان DevOps، مزایای بسیاری را به همراه می آورد.
یک تیم به وسیله DevOps، علاوه بر عملکردها (functionality) به پایداری (stability) هم اهمیت می دهد. هر یک از اعضای تیم خود را مالک و مسوول اهداف کسب و کار می داند. تناوب و تکرار انتشارها، تغییرات کوچک، و ابزارهای پایش مانند New-Relic و Boundary به پیشرفت و بهبود محیط های عملیاتی، زیرساخت ها و پایداری سورس-کد ها کمک می کنند.
یکی از سنجه های ویژه در اهمیت به پایداری، تناوب و تکرار انتشارها است. دِوآپس، به مهندسان این امکان را می دهد که بتوانند سریعتر عیب یابی کنند و خطاها را برطرف کنند. این دسته از تمرین ها باعث کاهش شاخص MTTR می شوند. Mean-Time-To-Recover یک متریک بسیار مهم به این معنی است که نشان می دهد سرعت برگشت به وضعیت پایدار در زمان وقوع یک حادثه چقدر است. بنابراین بعد از یک failure در زیرساخت، بسیار سریعتر می توان پایدار را به سرویس بازگرداند.
نرم افزارهای مانیتورینگ اپلیکیشن ها و سرورها مانند New Relic و Boundary با فراهم کردن دسترسی مهندسان به اطلاعات حیاتی نرم افزار و محیط عملیاتی، به شناسایی خطاها کمک می کنند تا پایداری را حفظ کنند.
ترکیب همه ی این ابزارها و به-روش ها (Best Practices) همراه با خودکارسازی (automation) به تیم های DevOps اجازه می دهند تا پایداری کلی سرویس را بهبود ببخشند و خرابی های بحرانی زیرساختی را کاهش دهند. علاوه بر این، آن ها را قادر می سازد تا در آن هنگام سریعتر و چابک تر رفتار کنند.

ماهیت سریع و چابک تیم های DevOps تیم ها را قادر می سازد تا قابلیت های جدید را در قالب گسترشهای کوچک تر و ماژولارتر معرفی کنند. از آنجا که این استقرارها بیشتر هدفمند و ایزوله هستند، شناسایی باگ ها آسانتر است، رفع آن ها سریع تر انجام می گیرد و پیاده سازی آن ها نیز آسان است. فقط لازم است که تیم ها آخرین تغییراتی کد را مجددا بررسی کنند تا بتوانند مشکلات را رفع کنند.
این رویکرد مزایای قابل توجهی هم برای کسب و کارها دارد. امکان رفع سریع تر خطاها باعث رضایت مشتریان شده و منابع ارزشمند را آزاد می کند و می توان این منابع را بر اعمال دیگری مثل طراحی، توسعه و استقرار عملکردهای و ویژگی های جدید متمرکز کرد. استفاده ترکیبی از سیستم های کنترل نسخه(Version-Control)، یکپارچه سازی مستمر (Continuous-Integration)، ابزارهای استقرار خودکار (Deployment-Automation-Tools) و توسعه مبتنی بر تست (TDD) به تیم های DevOps این امکان را داده است که تغییرات را در بخش های کوچکتر و به صورت افزایشی (incremental) اعمال کنند.
به دلیل این پیاده سازی های ماژولارتر، تیم های DevOps می توانند زودتر مشکلات مربوط به پیکربندی، کدهای اپلیکیشن و زیرساخت را کشف کنند؛ زیرا بعد از اتمام کدنویسی، مسئولیت به تیم دیگری محول نمی شود.
به دلیل اعمال تغییرات به صورت کوچکتر و تدریجی، مشکلات، پیچیدگی کمتری داشته و تصمیم گیری برای رعفع آن ها سریع تر انجام می شود زیرا مسئولیت خطایابی و رفع مشکلات فقط متوجه یک تیم خاص می شود.
گزارش State of DevOps که هر ساله توسط Puppet Labs منتشر می شود، در سال 2015 نشان می دهد که، شرکت های IT با عملکرد و بهره وری بالاتر نسبت به رقبای خود با عملکرد ضعیف تر، بعد از fail شدن، 168 بار سریع تر قادر به جبران آن و بهبود وضهیت هستند.

با ترکیب چندین تیم و رشته به صورت یک تیم DevOps ناب و معتدل که مجموعه مهارت هایی با عملکرد متقابل داشته و به صورت کارآمد و موثر با هم ارتباط برقرار می کنند، شما به صورت خودکار انباره های سنتی را که به دلیل چند قسمتی شدن بوجود آمده اند را در هم شکسته و تجزیه می کنید. به این ترتیب دیگر هیچ کدام از متخصصین عامل شکست نخواهند بود. همه افراد تیم مسئولیت رسیدن به اهداف کاری را بر عهده می گیرند و به دلیل ماهیت مشارکتی DevOps اعضای تیم می توانند چندین چالش در حوزه های مختلف عملیاتی و توسعه را به عهده بگیرند. البته این رویکرد مزایای زیادی برای یک سازمان دارد و تیم ها را قادر می کند که اعمال را به سرعت و به صورت موثر انجام داده و در عین حال کیفیت و ثبات را حفظ کنند.
![[عکس کاهش هزینه ها]](http://hidevops.com/wp-content/uploads/2018/04/cost-reduction.jpg)
با پیاده سازی یک رویکرد DevOps می توانید هزینه ها و منابع مورد نیاز در پیاده سازی های سنتی IT را کاهش دهید. IT به صورت سنتی به عنوان یک مرکز ایجاد هزینه تلقی می شد اما پیاده سازی DevOps نشان داد که این رویکرد ارزش های کاری واقعی ایجاد می کند. وقتی از رویکردهای مدیریت ناب و ارائه مستمر استفاده می کنید، نتایج کیفی بالاتر و طول چرخه ها کوتاه تر می شود و در نهایت هزینه ها نیز کاهش می یابند. این رویکرد به کاهش منابع مورد نیاز از نظر سخت افزار و نیروی انسانی نیز ادامه می دهد. یک معماری ماژولار از اجزایی تشکیل شده که بخوبی بسته بندی شده و ارتباط کمی با هم دارند و به سازمان ها اجازه می دهد که از رایانش ابری به صورت موثر و کارآمد استفاده کنند.
رایانش ابری از طریق استفاده از فرایندهای خودکار و طراحی قوی، سرویس ها و محصولاتی را فراهم کرده که توانایی تطبیق با نیازهای مشاغل را دارند. مزایای رایانش ابری بی شمار هستند و همه این مزایا به کاهش هزینه ها کمک می کنند. هر چند DevOps و رایانش ابری نه متقابلا منحصربفرد و نه مستقیم به هم مرتبط هستند، اما در صورتیکه با هم ترکیب شوند یکدیگر را تقویت می کنند.
انعطاف پذیری ایجاد شده توسط فناوری ابری، تیم های DevOps را قادر به تامین سریع تر نیازهای مشاغل و مشتریان می کند. اگر نیاز به منابع بیشتر یا یک دیتابیس جدید و یا سرورهای تعادل بار باشد، فناوری ابری امکان تحویل خودکار این نیازها را در عرض چند دقیقه فراهم می کند.
همچنین سرویس های رایانش ابری در مواقع بازیابی از حادثه کمک کننده هستند؛ زیرا بیشتر مشکلات توسط ارائه دهنده سرویس مدیریت می شوند.
همچنین، بروزرسانی های خودکار نرم افزار و زیرساخت، که به صورت سنتی درخانه انجام می شد، به ارائه دهندگان ابری محول می شود. در نتیجه زمان و منابع مورد نیاز در قسمتهای دیگر آزاد می شود.
مزایای دیگری که به کاهش الزامات مربوط به هزینه ها و منابع کمک می کنند، عبارتند از: حداقل شدن هزینه های شروع و هزینه های عملیاتی انجام پروژه، افزایش مشارکت، افزایش دسترس پذیری و دسترسی به داده ها و بهبود امنیت.
![[عکس افزایش کارایی]](http://hidevops.com/wp-content/uploads/2018/04/increased-performance.jpg)
در محیط های سنتی IT، زمان و منابع زیادی به هدر می روند. معمولاً برای انتظار جهت تکمیل کارها توسط دیگران یا حل چندین بارهی یک مشکل، زمان زیادی هدر می رود و این امر باعث سرخوردگی و ایجاد هزینه های مالی می شود.
محیط های تولیدی استاندارد و ابزارهای اتوماسیون می توانند به پیش بینی پذیر شدن استقرارها و تحویل محصولات کمک کنند. این فرایندها، افراد را از انجام کارهای روتین رها کرده و به آن ها اجازه می دهد که بر جنبه های خلاقانه تر نقش شان متمرکز شده، برای کسب و کار ارزش بیشتری ایجاد کنند و در نهایت همه از سود آن بهره مند شوند.
پیچیدگی یا نوع سیستم هایی که این شیوه ها به آن ها اعمال می شود، فاکتور چندان مهمی نیست. مادامی که معماری نرم افزار با در نظر گرفتن قابلیت تست و قابلیت استقرار ایجاد شود، امکان افزایش کارایی بیشتر می شود.
در گزارش “2015 State of DevOps Report” به چند نکته کلیدی اشاره شده که نشان می دهد تیم هایی با رویکرد Devops نسبت به رقیبانشان، از کارایی بالایی برخوردار بودند.
فکر میکنم شما هم موافق باشید که این افزایش قابل ملاحظه ای در عملکرد تیم ها است!
![[عکس خلاقیت و نوآوری]](http://hidevops.com/wp-content/uploads/2018/04/innovation.jpg)
همانطور که در بالا اشاره شد، معرفی ادغام مستمر/یکپارچه سازی مستمر/CI، استاندارد سازی محیط های تولید و استقرارهای خودکار/CD، کارشناسان را قادر می سازد تا بر جنبه های مبتکرانه و خلاقانه تر نقش شان بیشتر تمرکز داشته باشند. زمان و منابع بیشتری که صرف آزمایش و نوآوری می شود، به تیم ها امکان توسعه و انتشار نرم افزارهای بهبود یافته را داده و این امر مستقیما به رسیدن به اهداف بیزنسی ترجمه می شود. محیط و فرهنگی که DevOps به ایجاد و پرورش آن کمک می کند، به درک عمیق تر و پیاده سازی به-روش ها کمک می کند.
![[عکس رضایت شغلی]](http://hidevops.com/wp-content/uploads/2018/04/job-satisfaction.jpg)
به عنوان یک مهندس DevOps کاملا متعهد، می توانم با توجه به تجربیاتم به شما بگویم که کار کردن در یک محیط مشارکتی و چند مهارتی عامل بزرگی در زمینه رضایت شغلی است. من در نقشم به عنوان سرپرست توسعه دهندهی اپلیکیشن های وب، تمامی جوانب چرخه عمر محصول را مدیریت می کنم از مدیریت پیکربندی و زیرساخت گرفته تا توسعه، تست، اتوماسیون و استقرار. توانایی تشخیص مشکلات سرور، همزمان با دارا بودن مجموعه مهارت های لازم برای پیاده سازی اصطلاحات، سرمایه ای ارزشمند برای ما است.
اما دلیل اهمیت رضایت شغلی چیست؟
طبق گزارش سال 2014 Sate of DevOps “رضایت شغلی عامل شماره یک پیش بینی عملکرد (کارایی) سازمانی است.” یعنی رضایت اعضای تیم در انجام نقش شان عامل بسیار مهمی در افزایش کارایی شرکتی است.
شیوه ها و فرهنگ DevOps رضایت کارمندان را افزایش می دهد و این امر منجر به نتایج شغلی بهتر می شود.
![[عکس شکست های کمتر]](http://hidevops.com/wp-content/uploads/2018/04/fewer-failures.jpg)
داده های گزارش سال 2014 State of DevOps نشان داد که سازمان هایی که عملکرد خوبی دارند تعداد شکست هایشان (خرابی هایشان) 50 درصد کمتر است. این روند ادامه پیدا کرد و گزارش سال 2015 نشان داد که سازمان هایی که طرزتفکر و فرهنگ DevOps را اتخاذ کرده اند نسبت به آن هایی که رویکرد DevOps را پیاده سازی نکرده اند 60 برابر کمتر دچار شکست (خرابی) می شوند. این اطلاعات بسیار واضح هستند و مزایای عظیم DevOps را به عنوان یک طرز تفکر و فرهنگ برای مشاغل و البته افراد، مشخص کردند. شکست کمتر به معنی زمان بیشتر عملکرد سرویس و نیاز به منابع کمتر برای حل مشکلات است؛ در نتیجه به شما امکان می دهد که تمرکز بیشتری بر بهبودهای بیشتر و ابتکارات خلاقانه داشته باشید.
منبع: متن فوق برگرفته از سایت purplegriffon می باشد.
امیدوارم که توانسته باشم مزایای یک رویکرد DevOps را مشخص کرده باشم. فرهنگ فناوری اطلاعات مدام در حال تغییر است و روش های سنتی مدیریتِ انتشار محصولات، اغلب ناکارآمد، هزینه بر و زیانبخش هستند.
شاید کلمه DevOps، واژهای باشد که تازه باب شده است ولی قرار است ماندگار شود و در حال متحول کردن صنعت فناوری اطلاعات است.
افزایش کارایی، کاهش هزینه ها و تولید نرم افزار بهتری که شکست های (failure) کمتری داشته باشد مواردی هستند که تمام فروشنده های حوزه فناوری اطلاعات باید سعی به دستیابی به آنها داشته باشند. با استفاده از یک رویکرد DevOps این موارد قابل دستیابی تر هستند.
برای کسب اطلاعات بیشتر درباره DevOps و اینکه سازمان شما چطور می تواند تغییری فرهنگی به سمت پیاده سازی بهترین روش های DevOps داشته باشد با ما در ارتباط باشید.

شاخص های کلیدی عملکردی دواپس یا DevOps KPI که قبلا به چهار دسته سرعت، کیفیت، بهره وری و امنیت تقسیم کردیم را چطور ارزیابی میکنید؟ در این مطلب یازده شاخص کلیدی عملکرد، اصول و پایه های لازم برای ارزیابی موفقیت DevOps را معرفی و بررسی کرده ایم.
در مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” به دلیل اندازه گیری و ارزیابی سرعت اشاره کردیم. اما با چه سنجه و متریک هایی می توان سرعت را اندازه گیری کرد؟ در اینجا قصد داریم چهار شاخص عملکرد کلیدی سرعت دواپس را معرفی و شرح دهیم.
مفهوم: مشخص میکند که هر چند وقت یکبار نسخه جدیدی از یک محصول یا سرویس ارائه میشود. و به صورت تعداد استقرارها در ماه، هفته، روز یا ساعت ارزیابی می شود.
دلیل اهمیت: استقرارهای مکرر و پی در پی نشان دهنده بهبود مستمر اپلیکیشن ها است که با افزودن ویژگی های تازه به آن ها، باعث ایجاد قابلیت رقابت در آن ها می شود. همچنین بروزرسانی های مکرر نشان می دهد که بخش IT در برابر تقاضای بیزینس برای ویژگی های جدید پاسخگو است. یک بیزینس در صورتیکه مشاهده کند که به جای شش ماه یکبار، هر ماه شاهد اضافه شدن ویژگی ها و امکانات جدید توسط بخش IT است، قدردان بخش IT خواهد بود. (اما فراموش نکنیم که استقرار بیش از حد مکرر ممکن است نشان دهنده این باشد که به دلیل عجله زیاد، مدام نرم افزارهای معیوب تولید می کنید.)
همچنین این معیار به سایر حوزه های استقرار نرم افزار که عملکرد درستی دارند هم اشاره می کند:
قبلا دو مطلب در رابطه با استقرار نرم افزار منتشر کردیم که خواندن آن خالی از لطف نیست :
مفهوم: یک استقرار واحد، برای یک محصول یا سرویس خاص چقدر زمان می برد. این معیار به صورت تعداد ساعات سپری شده از تایید استقرار تا اجرای آن در محیط بعدی بیان می شود.
دلیل اهمیت: در روش های سنتی، سیستم های شرکتی اتصال تنگاتنگی دارند(tightly coupled هستند)؛ هر زمان چیزی مستقر می شود، ممکن است در نهایت نیاز به استقرار مجدد کل اپلیکیشن باشد. یک دهه پیش، این امر قابل قبول بود – می توانستید از کار افتادگی پنج ساعتهی ویندوز را برای نیمه شب زمانبندی کنید، بدون این که این از کار افتادگی تاثیر منفی برای بیزینس داشته باشد. اما مشاغل امروزه جهانی هستند – مثلاً وقتی در امریکا نیمه شب است، در آسیا روز است – و اکثر شرکت ها در همه اوقات مشتریانی دارند که بیدار هستند. بنابراین سریع بودن استقرار امری حیاتی است.
امروزه، سیستم ها باید کمتر به هم وابستگی داشته باشند. به این ترتیب، می توان سرویس های خاص را بدون تاثیر بر کل سیستم تغییر داد. با استفاده از میکروسرویس ها و APIهایی که به وضوح تعریف شده و امکان کپسوله کردن و دسترسی آسان را فراهم کنند، می توانید سرعت استقرار را به میزان زیادی افزایش دهید.
بعلاوه افزایش سرعت استقرار نشان دهنده افزایش ثبات (سازگاری) در خط لولهی دواپس (DevOps Pipeline)، با جایگزینی کارهای دستی پرخطا در چرخه عمر محصول، توسط اتوماسیون است.
مفهوم: کل زمان حرکت یک محصول در چرخه QA
دلیل اهمیت: اکثر اوقات QA تبدیل به یک تنگنا می شود. ارزیابی زمان سپری شده برای یک محصول تولیدی در QA اطلاعات کلیدی درباره اینکه با چه سرعت و فرکانسی می توانید یک محصول یا سرویس ارائه دهید، در اختیارتان قرار می دهد. وقتی مقدار این سنجه بالا باشد، متوجه می شوید که می توانید فرکانس را بدون اینکه QA تبدیل به تنگنا شود، افزایش دهید. اگر این مقدار پایین باشد، نشان می دهد که نیاز به پیاده سازی تکنیک هایی مثل اتوماسیون تست در خط لولهی انتشار محصول دارید (release pipeline).
مفهوم: تعداد تولیداتی که یک تیم QA می تواند در یک دوره خاص به مصرف برساند.
دلیل اهمیت: افزایش تعداد تولیداتی که QA می تواند به صورت مثبت مورد مصرف قرار دهد تاثیر مثبتی بر زمانبندی انتشار دارد. ممکن است سرعت استقرار بالا باشد، اما بدون ادغام مستمر (Continuous Integration) باید تولیدات را به صورت دستی مدیریت کنید که این کار باعث کند شدن خط لوله انتشار (DevOps Pipeline) می شود. به طور مشابه، بدون Continuous Testing، حین فرایند تست زمان هدر می رود. نتیجه این است که تیم QA نمی تواند حداکثر تعداد تولیدات را در هر چرخه به مصرف برساند و پوشش تست – همچنین اطمینان از حرکت به مرحله بعد – دچار مشکل است.
ادغام و تست مستمر می تواند فرکانس اعتبار سنجی تولید را افزایش دهد – در بعضی موارد می تواند آن را در هر ماه تقریبا دو برابر کند. وقتی که مقدار این عدد بالا باشد، نشان دهنده پوشش بهتر تست، نشان دهنده ی اطمینان بیشتر برای حرکت به مرحله بعد تولید و سرعت بیشتر تولید است.
پیرو مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” که در آن به دلیل اندازه گیری و ارزیابی کیفیت اشاره کردیم، در ادامه به سه تا از شاخص عملکرد کلیدی کیفیت در دواپس می پردازیم.
مفهوم: درصد استقرارهایی که بعد از اعتبار سنجی موفق تلقی شده اند. در اینجا موفقیت به این معنا است که بعد از استقرار، در فاصله ی کوتاهی مجبور به استقرار مجدد یا انتشار patch نشیم.
دلیل اهمیت: نرخ موفقیت بالا هنگام استقرار در سرورهای غیرتولیدی، دلالت بر کیفیت بالا در مراحل قبلی دارد. نرخ موفقیت پایین حاکی از ضعف کیفی کدنویسی است. در خیلی از شرکت ها، ممکن است System Integration Test و QA نرخ موفقیت بالایی داشته باشند ولی در عین حال در محیط پیش عملیات (Staging) موفق نباشند. این معیار می تواند به شما کمک کند تا مشکلات موجود در مرحله استقرار را هدف گرفته و از بین ببرید. نرخ موفقیت باید به مرور زمان افزایش پیدا کند.
در سازمان هایی که عملکرد خیلی خوبی دارند، مقدار این معیار باید به دلیل حذف مشکلات در پیش عملیات (Staging) – یا بهتر از آن، پیشگیری از این مشکلات – بالا باشد. اما خیلی از سازمان ها در این حوزه دچار چالش هستند و باید انتشارها (یا نسخه ها) را به عقب برگردانند. پایین بودن نرخ موفقیت بعد از یک فاز پیمایش موفق می تواند نشان دهنده چندین مشکل باشد:
مفهوم: تعداد حوادث و نقایص گزارش شده در یک نسخه خاص از یک محصول یا سرویس در محیط عملیاتی
دلیل اهمیت: حوادث و نقایص نشان دهنده از دست دادن زمان، پول و فرصت است. بالا بودن عدد این معیار نشان دهنده وجود مشکلاتی در حوزه های زیر است:
مفهوم: درصد قابلیت ردیابی (traceability) بین نیازمندی ها و تست ها (منظور امکان ارتباط دادن این دو به هم است).
دلیل اهمیت: عدم سازگاری بین نیازمندی ها و test case منجر به ایجاد مشکل و ضایعات حین چرخه استقرار نرم افزار می شود. وقتی که نیازمندی ها و test case ها به هم ارتباط نداشته باشند، تغییر در نیازمندی ممکن است منجر به شکست test case یا عدم وجود مواردی برای آزمایش شود. test case مشخص نمی کنند که چه تعداد از نیازمندی ها باید تحت پوشش قرار بگیرند و وقتی که تمامی نیازمندی ها را پوشش ندهند، این امر تاثیر منفی مستقیمی بر کیفیت نرم افزار و در نهایت بر تجربیات کاربر خواهد داشت.
وقتی که نیازمندی ها و test case ها با هم هماهنگی داشته باشند، تغییر در نیازمندی ها منجر به قابلیت مشاهده موارد متناظر در پوشش test case می شود. بروز رسانی هر یک از test case به نیازمندی ربط پیدا می کند. وجود ارتباط، تاثیر مثبت و مستقیمی بر کیفیت نرم افزار دارد. بالا بودن میزان این ارتباط نشان دهنده افزایش کیفیت نرم افزار؛ تناقض و ناسازگاری کمتر بین تحلیل گران، توسعه دهندگان و تیم QA؛ و بهره وری بالاتر است.
گروه دیگر از شاخص هایی که در مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” اشاره شد، بهره وری یا Productivity بود. در این خصوص نیز دو شاخص عملکرد کلیدی وجود دارد که شرح خواهیم داد.
مفهوم: تعداد یا درصد ویژگی های استفاده نشده از یک محصول یا سرویس خاص وقتی که تولید شده است.
دلیل اهمیت: DevOps یک چرخه بازخوردی است (feedback loop) که شامل بیزنس، توسعه، تست، عملیات و کاربران می شود. پایین بودن میزان استفاده از ویژگیها به این معناست که بخش فناوری اطلاعات (IT) مشغول توسعه ویژگی ها و امکاناتی است که یا مورد تقاضا نیستند (بازخورد ضعیف از سوی بیزنس به بخش توسعه)، یا مورد نیاز نیستند (بازخورد ضعیف از طرف کاربران به بیزنس) یا به صورت ضعیف ساخته شده اند (مشکل در بازخورد از سوی بخش IT). هزینه ویژگی ها و امکاناتی که مورد استفاده قرار نمی گیرند، می تواند بسیار زیاد باشد، بنابراین مهم است که علت این امر شناسایی شود. بالا بودن تعداد ویژگی هایی که در یک محصول خاص استفاده نشده اند نشان دهنده منفی بودن میزان اثربخشی مدیریت و توسعه نیازمندی ها است.
مفهوم: زمان بازیابی یک سرویس یا عملکرد، وقتی که در اثر وجود نقصی که نیاز به اصلاح یا توسعه دارد، اختلالی بوجود آمده باشد. به بیان دیگر وقتی که خطایی پیدا می شود، چقدر طول می کشد که آن خطا اصلاح شده و محصول عرضه شود؟
دلیل اهمیت: اگر اپلیکیشنی با تمام ویژگی ها و عملکردهای مورد نیاز منتشر کنید، ولی مشخص شود که این اپلیکیشن قابل اطمینان نیست یا بازیابی آن بعد از شکست زمان زیادی می برد، این امر باعث می شود تمام ارزش های ایجاد شده توسط تولید ویژگی ها و توابع مناسب در مراحل قبل از بین برود. مسلما نمی توان از هر نوع شکستی پیشگیری کرد اما می توان انعطاف پذیری اپلیکیشن ها و نحوه پاسخگویی تیم را بهبود بخشید. هر دقیقه از کار افتادگی یک سرویس، باعث از دست دادن درآمد، مشتری ها و کیفیت برند می شود.
بعلاوه، MTTRS می تواند مشخص کننده مشکلاتی در سازمان باشد از جمله:
سرعت، کیفیت و بهره وری بدون امنیت می تواند کل سرویس را به خطر بیاندازد. در مطلب قبل با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” به اهمیت اندازه گیری امنیت در دواپس اشاره کردیم و در ادامه دو تا از KPI های مهم در این خصوص را شرح خواهیم داد.
مفهوم: نسبت شکست در مقایسه با موفقیت در گذراندن اسکن امنیتی کدهای بعد از بیلد کردن محصول در یک دوره زمانی خاص.
دلیل اهمیت: مشخص شدن آسیب پذیری های امنیتی در مرحله تولید، به این موضوع را تضمین می کند که همیشه قبل ورود به سایر بخش های DevOps Pipeline، محصولاتی سبز و خوب تولید می شوند.
مفهوم: تعداد اسکن های امنیتی که در یک بازه زمانی یا فاز پردازش خاص، مشکلی را مشخص می کنند همراه تعداد مشکلات.
دلیل اهمیت: این نرخ باید با گذشت زمان یا با حرکت از مرحله ای به مرحله بعد در خط لوله کاهش پیدا کند. اگر نرخ موفقیت اسکن امنیتی رو به بهبود باشد، این اطمینان ایجاد می شود که سرعت توسعه و انتشار ویژگی های جدید طوری است که بجای آسیب رساندن به امنیت، باعث پایداری محصول می شود.

DevOps این قابلیت را دارد که زنجیره ارائه نرم افزار را به ماشینی با تفکر ناب، سریع و به شدت موثر تبدیل کند تا آنچه کاربران تقاضا دارند را عرضه کند. این تبدیل اهمیت بسیار زیادی دارد. طبق یکی از نظر سنجی های شرکت Forrester Consulting که در سال 2015 انجام شده، 64 درصد از پاسخ دهندگان بر این باورند که نرم افزار یکی از عوامل کلیدی توانمندساز مشاغل است و موفقیت مشاغل بستگی به اپلیکیشن هایی با کیفیت بالا دارد که مناسب با مدل های بیزنسی مدرن باشد.
DevOps has the potential to transform the software delivery chain into a lean, fast, highly effective machine that delivers what users want.
شرکت نرم افزاری HPE با کمک داده های حجیم معیارهایی را از منابع مختلف در سیستم های IT مختلف جمع آوری کرده است تا این 11 شاخص کلیدی عملکرد و موارد دیگر را تولید کند. ابتکار شرکت نرم افزاری HPE دیدگاهی واحد از معیارهای DevOps فراهم می کند که به شما برای بدست آوردن اطلاعات و بینش هایی درباره مسیر حرکت DevOps کمک می کند؛ به طوری که می توانید به شیوه ای موثر و کارآمد تبدیل و تحول DevOps را مدیریت کنید.
وقتی که شروع به استفاده از شاخص های کلیدی عملکرد برای ارزیابی موفقیت DevOps کردید، راه های زیادی برای گسترش داشبورد معیارهای دواپس و متناسب کردن آن با سایر سطوح سازمان خواهید داشت. برای گسترش معیارهای DevOps به سمت بالا و حوزه بیزنس، داشبورد KPIی DevOps را می توان به صورت یک داشبورد مخصوص مدیر ارشد فناوری اطلاعات درآورد که دیدگاهی سطح بالا از تشکیلات IT و همچنین میزان پیشرفت در فعالیت های عمده فراهم کند. (DevOps Dashboard)
یکی از شاخص های کلیدی عملکرد که در حال حاضر مشاغل علاقه زیادی به آن دارند، میزان استفاده از ویژگی ها است اما می توانید در کنار آن، زمان چرخه را هم نظارت کنید که نشان می دهد تولید یک ویژگی خواسته شده و استقرار آن در یک محصول چقدر زمان می برد. البته شاخص های کلیدی عملکرد از نوعِ اقتصادی نیز همیشه برای مشاغل متناسب و مهم هستند – که یکی دیگر از راه های گسترش داشبورد را تشکیل می دهند.
بعلاوه می توانید داشبورد DevOps را به سمت پایین هم گسترش دهید تا فعالیت های روزمرهی افراد را تحت پوشش قرار دهد.
DevOps یک سفر و یک سیر تکاملی است نه یک پیاده سازی یک شبه. هر چند خیلی از ابتکارات با برداشتن قدم های کوچک شروع می شوند، اما DevOps نیاز به تعهد به یک نوع فرهنگ جدید دارد. به همین خاطر است که شرکت هایی که امروزه به دنبال پیاده سازی دواپس هستند، احتمالا نیاز به تحویل طرح فعالیت تجاری جدید به مدیران سازمان دارند. سازمان های دیگری که از قبل دواپس را آزمایش و تجربه کرده اند، ممکن است آماده باشند که اطلاع را جمع آوری و رویکردشان را بهینه سازی کنند. در هر صورت وجود معیارهای قابل رویت و مفید در موفقیت DevOps تاثیر بسیار زیادی دارد.
منبع : “Hewlett Packard Enterprise, “Measuring DevOps success
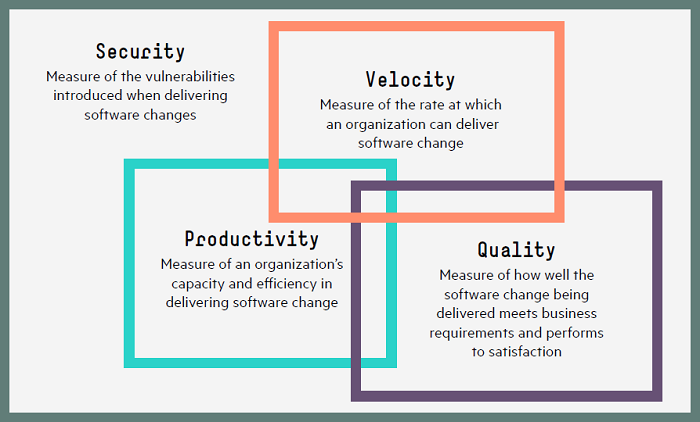
امروزه و در عصر DevOps، پیوسته لازم است که شاخص های کلیدی عملکرد (KPI) را ارزیابی کنید تا میزان موفقیت DevOps مشخص شده و امکان تغییرات بیشتر فراهم شود.
DevOps در اصل از طریق جنبش چابک (Agile Movement) رشد پیدا کرد و در واقع راهکاری برای افزایش سرعت ارائه نرم افزار توسط تیم های توسعه نرم افزار به مشتریان است. در حال حاضر DevOps دربرگیرنده همه بخش های فرایند ارائه نرم افزار است از برنامه ریزی گرفته تا ایمن سازی، نظارت و بروز رسانی اپلیکیشنی که از قبل تولید شده است.
امروزه، DevOps به طور گسترده برای build، تست و ارائه نرم افزار توسط کسب و کارهای مختلف پذیرفته شده است. در این دنیای رقابتی، پرتحرک و همیشه متصل، DevOps شرکت ها را قادر ساخته که از طریق از بین بردن سیلوهای توسعه (Dev) و عملیات (Operation)، با خواسته ی کاربران در مورد تحویل و ارائه سریع همگام شوند.
این شرایط اهمیت کیفیت نسبت به گذشته را دوچندان کرده است؛ در نتیجه کسب و کارها نمی توانند صرفا برای ارائه سریع نرم افزار به بازار، کیفیت را نادیده بگیرند. با ارائه ی یک اپلیکیشن با عملکرد ضعیف در یک فروشگاه اپلیکیشنی (app store) که کاربران نظرات منفی زیادی در آن درج می کنند، به سرعت می توان شهرت و خوشنامی یک برند را از بین برد. با استفاده از DevOps، بهینه سازی کارها در جهت افزایش سرعت، همزمان با حفظ کیفیت و کاهش خطرها قابل انجام است. Batchهای کوچک، سریع تر ارائه شده و به صورت ذاتی مشکلات مربوط به کیفیت و امنیت را کاهش می دهد.
افزایش سرعت در توسعه نرم افزار به روش سنتی، اغلب اوقات باعث کاهش کیفیت و افزایش آسیب پذیری می شود. همچنین در روش های سنتی افزایش سرعت، کیفیت و امنیت عاملی برای افزایش هزینه ها محسوب می شود. اما ابتکارات DevOps می تواند واقعا منجر به بهبود در تمام این چهار بُعد شود: سرعت، کیفیت، بهرهوری و امنیت. کلید کار اتخاذ چارچوبی برای معیارها است که مشخص کند چه جاهایی در حال پیشرفت هستید و چه جاهایی هنوز نیاز به بهبود دارید.

اکثر سازمان ها DevOps را به دلیل یک نیاز بیزینسی خاص مثل بهبود زمان بازاریابی، کاهش نقایص یا تراز کردن بهتر ابتکارات IT با استراتژی بیزینسی پیاده سازی می کنند. اما از آنجا که DevOps هیچ فریم ورک رسمی ندارد، روش های زیادی برای ارزیابی موفقیت DevOps وجود ندارد، در حالیکه این ارزیابی حیاتی است. از آنجا که خیلی از سازمان ها DevOps را به صورت تدریجی پیاده سازی می کنند – اول در یک پروژه و بعد آرام آرام آن را در سراسر سازمان گسترش می دهند – چند پروژه اول باید موفقیت آمیز باشند؛ طوریکه بتوانند پشتیبانی انحصاری برای DevOps ایجاد کنند. همانطور که مشتریان ما به ما گفته اند: “هر چیزی که ارزیابی شود، بهبود پیدا می کند.”

وجود معیارهایی که نشان دهنده موفقیت آمیز بودن یک آزمایش باشند، می تواند به غلبه بر مقاومت های داخلی در برابر پذیرش DevOps کمک کند. یکی از نظرسنجی های شرکت Gartner از مدیران مشاغل2 و بخش IT مشخص کرد که “people issue” (موارد مربوط به افراد) بزرگترین چالشی است که سازمان ها در پذیرش DevOps با آن روبرو هستند و 43 درصد پاسخ دهندگان مقاومت در برابر تغیرات را بزرگترین مانع دانسته اند. از آنجا که DevOps نیاز به تحول فرهنگی و تغییرات فرایند و فناوری دارد، وجود پشتیبانی و حمایت انحصاری از آن ضروری است.
بعلاوه، DevOps به عنوان یک سیر تکاملی شناخته شده است که نیاز به بهبود مستمر (Continuous Improvement) دارد. اما اگر نتایج را ارزیابی نکنید، متوجه نمی شوید که DevOps را چطور درون سازمانتان تکامل دهید.
ارزیابی در مسیر تکامل DevOps بسیار ضروری و حیاتی است. اما چطور می توان موفقیت DevOps را ارزیابی کرد؟ چه چیزی باعث عملکرد فوق العادهی یک سازمان می شود؟ کدام شاخص های کلیدی عملکرد (KPI) این قابلیت را دارند که مشخص کنند چه چیزی برای شما خوب کار می کند و چه چیزی خیر – و اطلاعاتی برای توضیح علت (علت کار نکردن بعضی روش ها) فراهم کنند؟ چه چیزهایی را ارزیابی می کنید، چطور آن ها را ارزیابی می کنید و این اعداد دقیقا چه چیزی را نشان می دهند؟
این مقاله یازده شاخص کلیدی عملکرد را مشخص کرده که فنداسیون لازم برای معیارهای DevOps را ایجاد می کنند، رشته ای که همگام با تکامل روش های DevOps بیشتر و بیشتر درون شرکت هایی در انواع مختلف تنیده می شود. این یازده شاخص را در پست بعدی معرفی و بررسی خواهیم کرد.

برای تعیین بهترین شاخص های کلیدی عملکرد (KPI) جهت ارزیابی DevOps، شرکت Hewlett Packard Enterprise Software Services (به اختصار HPE) در ابتدا بزرگترین چالش های ارائه نرم افزار را که مشتریان گزارش شده بود را بررسی کرده است:
هر یک از این چالش ها به تنهایی می تواند موانعی برای یک شرکت در جهت برآورده کردن خواسته های کاربران ایجاد کند. هر یک از این چالش ها به تنهایی، در توانایی یک شرکت برای برآورده سازی تقاضاهای کاربران مانع ایجاد می کند. اما تقریبا هر شرکتی حداقل با سه یا چهار مورد از این چالش ها روبرو می شود و خیلی از شرکت ها با تمام این پنج چالش روبرو می شوند. جای تعجب نیست که خیلی از تیم های نرم افزاری اطلاع ندارند که کجا یا چطور شروع به اصلاح مشکلاتشان کنند.
شرکت HPE ریشه این مشکلات را چهار حوزه متفاوت می داند:
DevOps می تواند تمام این چهار مورد را بدون از دست رفتن هیچکدام برآورده کند. موفقیت در هر یک از این چهار حوزه می تواند زمان عرضه به بازار، تجربیات کاربر، هزینه، پیش بینی پذیری و امنیت را کاملاً بهبود ببخشد.
شرکت HPE، رهبری تعریف معیارهایی که شرکت های امروزی باید ارزیابی و نظارت کنند را بر عهده گرفته است. بعضی از بزرگترین مشتریان DevOps در حال حاضر این فریم ورک را قبول و پیاده سازی کردهاند.
سرعت (Velocity) : نرخ ارائه تغییرات نرم افزاری توسط یک سازمان را ارزیابی می کند.
کیفیت (Quality) : ارزیابی می کند که تغییرات نرم افزاری ارائه شده چقدر نیازهای کسب و کار را برآورده و در جهت رضایت عمل می کنند.
بهره وری (Productivity) : ظرفیت و کارایی یک سازمان در تحویل تغییرات نرم افزاری را ارزیابی می کند.
امنیت (Security) : آسیب پذیری هایی که هنگام تحویل تغییرات نرم افزاری نمایان می شوند را ارزیابی می کند.
سرعت، کیفیت، بهره وری و امنیت به یکدیگر وابسته اند. بهبود یک حوزه منجر به بهبود در سه حوزه دیگر می شود بدون این که نیازی به tradeoff باشد.
مهم ترین ویژگی DevOps سرعت است. DevOps به عنوان راهی برای عرضه سریع امکانات جدید توسط توسعه دهندگان در پاسخ به تقاضای کاربران برای محتوای سریع تر و بهتر، ایجاد شده است. و با توجه به اینکه سرعت، امری نسبی است –احتمالا همیشه می خواهید که سریع تر و سریع تر از قبل باشید– بیشتر تیم های توسعه دهنده فراموش می کنند که به دنبال چه هدفی هستند.
با اندازه گیری و ارزیابی سرعت متوجه می شوید که آیا در حال افزایش سرعت هستید یا کاهش آن و یا اینکه در یک الگوی خاص گرفتار شده اید. همچنین می توانید به بیزینس کمک کنید که به طور واضحتری میزان پاسخگویی بخش IT را مشخص کند.
سرعت زیاد در تحویل نرم افزار، علاوه بر ایجاد مزیت رقابتی برای شرکت، نحوه تعامل کسب و کار با بخش IT را هم بهبود می بخشد.
طبق نظرسنجی ای1 که شرکت Forrester Consulting از تصمیم گیرندگان IT امریکایی و اروپایی انجام داده است، 78 درصد از پاسخ دهندگان بهبود کیفیت را یکی از خواسته های اصلی گروه های بیزینسی اعلام کرده اند.
با DevOps نیازی به قربانی کردن کیفیت برای رسیدن به سرعت بیشتر نیست. برای افزایش سرعت می توانید ارائه نرم افزار را به واحدهای کوچکتری تقسیم کنید، به طوریکه در واقع تعدادی micro service با وابستگی حداقلی یا بدون هیچ وابستگی ارائه خواهید کرد. unitهای کوچکتر یعنی تحویل سریع تر به همراه کیفیت بالاتر و ریسک کمتر.
بعلاوه DevOps از طریق ایجاد فرهنگی برتر و ابزارهایی برای پشتیبانی از آن، کیفیت را وارد تمامی مراحل زنجیره ارائه نرم افزار می کند.
از نظر فرهنگی، DevOps بر مسئولیت های مشترک، انتظار کیفیت از توسعه دهندگان، تست کنندگان، اعضای تیم امنیت و عملیات و همه افراد بین آن ها تاکید دارد. از نظر تکنیکی، DevOps مستلزم حداکثر میزان ممکن اتوماسیون برای سرعت بخشیدن به فرایندها و کاهش خطاهای انسانی است. و استفاده از یک رویکرد Shift-left در تست، امنیت و مانیتورینگ به بهبود کیفیت کمک می کند.
shift left testing رویکردی در تست نرم افزار یا سیستم است که بر انجام تست در مراحل اولیه چرخه حیات تاکید دارد (moved left on project timeline). این نیمه اول قاعده کلی تست نرم افزار است: “تست زودتر و پر تکرار” (Test Early and Often)
کیفیت چیزی نیست که قابل حدس زدن باشد. بلکه باید آن را توسط معیارهای خاص تعریف و بر این اساس بر آن نظارت کرد.
همه ی هدف و تمرکز DevOps این است که به سازمان های فناوری اطلاعات کمک کند تا ارزش بیشتری برای بیزینس ایجاد کند. اما در صورتیکه تلاش های شما بخوبی با بیزینس هماهنگ نشده باشد، هر چقدر هم سریع بتوانید نرم افزارهایی با کیفیت عرضه کنید، این امر (ایجاد ارزش برای بیزینس) میسر نمی شود.
در صورتیکه DevOps درست اعمال شود، سازمان ها شاهد افزایش سرعت و کیفیت بدون افزایش هزینه ها خواهند بود. در حقیقت با کوتاه کردن چرخه ها، شما شاهد افزایش ارزش های کسب و کاری خواهید بود. ارزیابی و نظارت بر معیارهای بهره وری، یک چرخهی بازخورد (feedback loop) برای بخش IT ایجاد می کند. بدین ترتیب تمرکز خود را بر ایجاد ویژگی هایی که مورد استفاده کاربران است می گذارید و در نتیجه اتلاف منابع کمتر صورت می گیرد و و ارزش بیزینسی افزایش می یابد.
سرعت اهمیت زیادی در DevOps دارد اما در دنیای امروزی، اهمیت امنیت هم به همین اندازه زیاد است. تیم ها باید اطمینان داشته باشند که حین عملیات، باعث آسیب پذیر شدن سیستم نمی شوند.
افزودن ویژگی های جدیدی که باعث ایجاد آسیب پذیری های جدیدی در سیستم شود یا آسیب پذیری ها و نقاط نفوذ قبلی را مشخص کند، مطمئنا باعث نارضایتی مشتریان خواهد شد. بعلاوه ایجاد آسیب پذیری در سیستم باعث می شود که تیم ها مجبور شوند بیشتر وقتشان را صرف اصلاح این آسیب پذیری ها و نقاط ضعف کنند.
امنیت هم مثل کیفیت به رویکردهای تست shift-left نیاز دارد که با استفاده از این رویکرد مشخص کردن زود هنگام آسیب پذیری ها با هزینه های کمتر (هم از نظر زمانی هم از نظر هزینه های مالی) قابل انجام است. وقتی که تست shift-left را انجام دهید، تست امنیت در ابتدای چرخه توسعه انجام می شود. ارزیابی زود هنگام آسیب پذیری های امنیتی این اطمینان را ایجاد می کند که تولیدات قبل از این که به مرحله بعدی خط انتشار وارد شوند، پایدار و باثبات می شوند.
بعلاوه ارزیابی امنیت می تواند به مقابله با مقاومت ها در برابر پذیرش DevOps کمک کند. از آنجا که آسیب پذیری ها کاهش پیدا می کنند، می توانید نشان دهید که افزایش سرعت باعث تنزل پایداری یک محصول نمی شود.
در مطلب بعد یازده شاخص کلیدی عملکرد DevOps را معرفی و بررسی خواهیم کرد.
برگرفته از “Hewlett Packard Enterprise, “Measuring DevOps success
سایر منابع :
1Source: Forrester Consulting, “Application Delivery Speed Drives Success: How Mastering DevOps Enables Speed With Quality and Low Cost”
2–3Source: Gartner, “Survey Analysis: DevOps Adoption Survey Results,” September 2015

به روز رسانی این چارچوب در سال 2018 صورت خواهد گرفت. با وجود هسته پایه ای از بهترین شیوه های موجود در راهنمای ITIL# ، این به روز رسانی، محتوای تمرین جدید و صریحی را با تمرکز بر ادغام بهینه ی ITIL با شیوه های تکمیلی مانند DevOps ، و Agile و Lean ارائه میدهد.
تکامل این چارچوب، از تجارب واقعی هزاران متخصص و کارشناس حاصل خواهد شد. در حال حاضر همکاران انجمن جهانی ITSM شامل برندهای بین المللی، SMEs، دولت ها، دانشگاهیان، سازمان های آموزشی و جوامع حرفه ای هستند. در حال حاضر بیش از 650 متخصص در سراسر جهان در برنامه تحقیقاتی ITIL مشارکت دارند.
Peter Hepworth ، مدیر عامل شرکت #AXELOS، در سخنرانی کنفرانس ItSMF USA Fusion 2017 اظهار داشت:
ITIL یک ابتکار عمل مبتنی بر جامعه است . من هم اکنون درحال تشویق متخصصان فناوری اطلاعات جهت پیوستن به برنامه تحقیقات جهانی خود هستم. این کار فرصتی برای همکاری خواهد بود.
تحقیقات وسیع AXELOS در میان جامعه مدیریت خدمات جهانی نشان داده است که چارچوب اثبات شده و آزمایش شده ITIL همچنان ستون فقرات شیوه های کسب و کار امروز است و به طور قابل توجهی باعث تسهیل تحول در کسب و کار می شود. بیش از یک میلیون متخصص فناوری اطلاعات در ایالات متحده به راهنمایی بهروش های ITIL برای به دست آوردن موفقیت در کسب و کار تکیه کرده اند و هر ساله سازمان ها، در اتخاذ ITIL، انطباق آن با نیازهای خود و بالا بردن مهارت هایشان با شرایط ITIL به طور قابل توجهی سرمایه گذاری می کنند. به عنوان بازتابی از این امر، این به روز رسانی شامل اصول هسته ای پذیرفته شده ITIL، که در حال حاضر ارزش واقعی را برای سازمان ها در سراسر جهان ارائه می دهد، خواهد بود.
انعطاف پذیری و چابکی در سال های اخیر تبدیل به یک اولویت شده است، زیرا سازمان ها ، فناوری ها و روش های کار جدیدی مانند cloud و سطح بالایی از اتوماسیون و تحول دیجیتال را اتخاذ می کنند. این جنبش وابسته به به روز رسانی ITIL است : این امر اطمینان حاصل خواهد کرد که متخصصان مدیریت خدمات IT در جهان با اطمینان می توانند دانش لازم ITIL خود را با این روش های کسب و کار جدید ادغام کنند.
Peter Hepworth ادامه داد:
“طی 18 ماه گذشته، AXELOS با صدها نفر از متخصصان در انجمن مدیریت خدمات مشغول به فعالیت بوده است. آنها تأیید کرده اند که ITIL، با چارچوب اثبات شده خود، همچنان باقی خواهد ماند. با استفاده از این به روز رسانی، می توانیم از این نقاط قوت بهره ببریم و ITIL را پاسخگو تر، شفاف تر و سریع تر کنیم. ”
این تحقیق AXELOS ، ارزشی را که این گواهی نامه ها برای متخصصان ITSM داشته اند را نشان میدهد. این گواهینامه ها به عنوان صنایع شناخته شده اند و به عنوان پیش نیاز برای بسیاری از حرفه ای های فناوری اطلاعات درنظر گرفته شده است. با این شناخت ، AXELOS اطمینان خواهد داد که شرایط فعلی ITIL در طرح جدید معتبر بماند.
Cathy Kirch ، رئیس شرکت itSFM ایالات متحده آمریکا، برگزار کننده FUSION 2017 و از پیشگامان چارچوب حرفه ای متخصصان مدیریت خدمات فناوری اطلاعات در ایالات متحده، اظهار داشت:
ITIL قوی ترین چارچوب ITSM در زیرساخت سازمان های بزرگ و پیچیده است و بسیاری از آنها و یا دست کم 500 شرکت از آن استفاده می کنند. در حال حاضر، ITIL و دیگر شیوه های تکمیلی مانند DevOps، Agile و Lean ، در ارتباط با یکدیگر به طور موفق مورد استفاده قرار می گیرند، هرچند تکامل بعدی ITIL، همکاری دینامیکی را ترویج و پایه گذاری می کند.
” itSMF ایالات متحده آمریکا ، این بروز رسانی را فعالانه پشتیبانی می کند. ما اهمیت تحول ITIL را به رسمیت می شناسیم: برای اطمینان از این امر که همان گونه که محیط کسب و کار با افزایش سرعت تغییر می کند، متخصصان مدیریت خدمات نیز در حال کسب مهارت های حیاتی جهت رسیدگی به فن آوری های در حال ظهور و اتخاذ شیوه های جدید هستند.”
“ما مشتاق هستیم که اعضایمان این برنامه تحقیق جهانی ITIL را پیش ببرند. این امر بستگی به نقش آنها در ایجاد ITIL برای آینده دارد، چارچوبی که پرورش متخصصان ITSM را با منابعی که در قلب دگرگونی های کسب و کار باقی بمانند، ادامه خواهد داد. ”
Ref: AXELOS website

پایه و اساس DevOps ، تغییر است. Keep CALMS !
به وسیله DevOps، کسانی که با آخرین ابزارهای توسعه کار میکنند، محتاطانه عمل نمی کنند. DevOps علاوه بر افراد و فرایند ها، به ابزارها هم اهمیت می دهد و روش های مختلفی برای گرد هم آوردن این سه مجموعه در کنار هم ایجاد می کند.
کافی است تا عبارت “DevOps” را در google جستجو کنید تا دیاگرام ها و متدولوژی های بسیاری را پیدا کنید که هر کدام از آن ها جنبه ی متفاوتی را برجسته کرده اند. اما می توان گفت که همه ی آن ها در موارد زیر با هم مشترک اند:
به این چهار مورد اصول یا چارچوب CALMS در DevOps می گویند.
چارچوب CALMS را می توان در پنج واژه ی فرهنگ سازی، خودکارسازی، تفکر ناب، اندازه گیری و اشتراک گذاری برشمرد. (این موضوع در برخی مطالب با عنوان “اصول CALMS در DevOps چیست” مطرح شده است که چارچوب صحیح تر است، در آینده در مطلبی جداگانه اصول DevOps را معرفی خواهم کرد)
همه میدانیم فرهنگ چیزی نیست که یک نفر بتواند آن را پیاده سازی کند. فرهنگ در یک محیط طبیعی که شامل سرتاسر تیم تولید نرم افزار می شود وجود دارد. منظور از سرتاسر همه ی افراد است از جمله توسعه دهندگان (Development)، تضمین کنندگان کیفیت (QA) و تیم های عملیات (Operation) و … . در چنین اکوسیستمی که متشکل از مجموعه ای از افراد و ابزارها است، برای رفع موانع و تسهیل همکاری برای دستیابی به اهداف نهایی، یک کار فرهنگی لازم است.
هیچ چیز زشت درباره فرهنگ وجود ندارد.
فرهنگ سازمانی نقش اساسی در موفقیت یک کسب و کار ایفا می کند، به همین دلیل پرداختن به آن بسیار مهم و ضروری است. فرهنگ در DevOps، یک خط قرمز است. زمان صرف شده در فعالیت های غیر ضروری، سیلوهای مسوولیت، دیوار بین تیم ها و تعاملات نامناسب از جمله مهمترین موانع در رسیدن یک سازمان به اهدافش هستند. DevOps توصیه می کند که تیم ها را از سیلو هایشان خارج کنید و دیوار بین آن ها را بشکنید تا با هم تعامل بهتری داشته باشند. با همسو کردن اهداف متفاوت تیم ها، به هدف اصلی سازمان یعنی ایجاد و تحویل ارزش به برسید.
هنگامی که فرهنگ سازی در سازمان انجام شد، می توانید بر خودکارسازی یا اتوماسیون تمرکز کنید. اتوماسیون تنها به نوشتن Script ها و استفاده از Unit Test ها یا Functional Test ها محدود نمی شود. خودکارسازی شامل همه قسمت ها از جمله Continuous-Integration ، Continuous-Delivery/Deployment، Infrastructure-Automation و هر جای دیگری می شود.
با راه اندازی Automation می توانید برای همه چیز برنامه ریزی کنید.
فرایند های دستی بسیار کند و مستعد خطای انسانی هستند. راهی برای رهبری تمامی ابتکارات جدید به وسیله اتوماسیون پیدا کنید و برای رسیدن به مقیاس های بزرگتر به طور مستمر به اتوماسیون فکر کنید.
بعد از راه اندازی اتوماسیون، به یاد داشته باشید که همچنان ناب بمانید و اصول تولید ناب نرم افزار را رعایت کنید.
اجرای Lean به معنی نگه داشتن همه چیز در حداقل است.
ابزارها، جلسات و حتی iteration ها و همه چیز دیگر باید Lean باشد یعنی در حداقل ممکن باشد. تفکر ناب یعنی ارزش محور بودن فعالیت ها و کاهش فعالیت های اضافه و در حداقل نگه داشتن همه چیز. این هم بخشی از فرهنگ DevOps است. وقتی شما ناب هستید، برای هر ابزار، و روشی که انتخاب می کنید، هدفی دارید.
ناب بودن تنها به یک یا چند فرد محدود نمی شود و شامل همه ی تیم ها و افراد می شود.
باید تیم را در اندازه ای نگه داشت که بیشترین کارایی را داشته باشد. یک آشپزخانه با آشپزهای بیش از حد، بازده کمی خواهد داشت. اگر پیچیدگی اپلیکیشن به گونه ای باشد که نیاز به تیم های بزرگ باشد، تیم را به زیرگروه های کوچکتر تقسیم کنید، همانطور که سازمان های بزرگ این کار را می کنند. (spotify یکی از موفق ترین مثال ها در این زمینه است)
اندازه گیری مانند چسبی است که همه چیز را در کنار هم قرار می دهد. زمانی شما یک سازمان چابک و ناب هستید که همه چیز را اتوماتیک می کنید، ممکن است که توانایی به خاطر سپردن و مستند سازی را از دست بدهید.
اگر تیمی در همه موارد شفافیت لازم را نداشته باشد و کارها اندازه گیری نشوند، در نهایت اشتباهات بزرگی رخ خواهد داد.
اگر اندازه گیری به روش صحیحی انجام شود، اشتباهات بزرگ رخ نمی دهد. در صورت اندازه گیری و گزارش گیری در همه ی تیم ها و فرایند ها است که قادر به تجزیه و تحلیل ارتباط بین فرایند ها، ابزارها و داده های محصولات در کنار خواهید بود. اندازه گیری به شما کمک می کند که نقاط ضعف را بشناسید و در جهت بهبود آن گام بردارید و در نهایت بتوانید روند پیشرفت را پایش کنید.
با این وجود نمی توانید با یک excel ساده این کار را انجام داد. در یک سازمان ناب، شما فرصت ندارید که همه چیز را به صورت دستی و غیر اتوماتیک ثبت کنید. این کار بسیار زمان گیر و مستعد خطای انسانی است.
اندازه گیری و جمع آوری داده ها باید با ابزارهای پیشرفته تری انجام شود. ابزارهایی که شامل قابلیت هایی فراتر از نظارت و گزارش گیری رویدادها هستند و می توانند بینش جدیدی به شما انتقال دهند. به این ترتیب می توانید از فکر کردن به نحوه دریافت و ثبت اطلاعات در عملیات مهم جلوگیری کنید و آن را به ابزارهایی با بستر مناسب بسپارید. بعد از آن که متوجه شدید به چه چیزهایی باید به طور مستمر نظارت داشته باشید، می توانید یک داشبورد بسازید که گویای تمام اطلاعات مهم و مورد نیاز باشد.
بعد از آنکه داده ها را جمع آوری کردید، باید اشتباهات و نحوه ی جلوگیری از آن و دانش جدیدی که از این راه بدست آوردید را منتشر کنید.
ایجاد جریان اطلاعات دوطرفه یکی از مزیت های شکستن دیوار بین تیم ها می باشد و باعث جلوگیری از انداختن توپ در زمین تیم دیگر می شود. با این وجود اگر اطلاعات به صورت proactive و فعالانه به اشتراک گذاشته نشوند، ارزشی نخواهند داشت.
Sharing و Reporting کاملا با هم متفاوت هستند، Sharing تنها گزارش واقعیات نیست، بلکه مبادله ی ایده ها در سر تا سر تیم ها و به طور دائمی است. Reporting معمولا به صورت انفعالی (reactive) اتفاق می افتد در حالی که Sharing به صورت فعالانه و proactive می باشد.
توسعه دهندگان می توانند به تیم های QA و عملیات، ابزارهای جدیدی برای ارتقا کیفیت محصول پیشنهاد بدهند، و تیم عملیات می تواند پیشنهاد ایجاد قابلیت هایی در نرم افزار را به تیم توسعه بدهد تا به مدیریت بهتر محصول کمک کند.
تمامی جریان های DevOps از جمله CALMS، مانند یک نقشه راه هستند، نه تعریف تمامی گام های لازم برای رسیدن به هدف. اگر با راهنما پیش بروید، حتما به هدف خواهید رسید، هر چند با راهکارها و گام های متفاوت.
چیزی که در توصیف CALMS از DevOps منحصر به فرد است، تاکید بر بعد فرهنگی DevOps است.
از CALMS برای رها سازی جهت بروز خلاقیت ها استفاده کنید، نه برای ردیابی عملکرد افراد
فرهنگ سازی، هیچوقت کار آسانی نبوده و نخواهد بود. برای شکل گیری فرهنگ و جا افتادن آن در سازمان زمان لازم است. در ابتدا این کار سخت است و ممکن است با ناسازگاری هایی روبرو شوید، اما بعد از مدتی به یک عادت تبدیل می شود.
CALMS یک نقشه راه است، نه تعریف تمامی گام ها و جزئیات لازم برای رسیدن به هدف، پس به یاد داشته باشید که به تنهایی کافی نیست.
داشتن iteration و ضرب آهنگ منظم و همچنین نتیجه گرا بودن، از موارد مهمی هستند که در CALMS به آن ها اشاره نشده است و می تواند مکمل CALMS باشند. از موارد دیگری که در CALMS به آن اشاره نشده، Security و امنیت محصول است، اما قطعا DevOps امنیت محصول را بهبود می دهد. تمامی موارد اشاره شده شامل بعد فرهنگی و فناوری می باشند.
به طور طبیعی اگر شما نتیجه گرا باشید، ذهن تحلیلگری دارید و با افرادی که همکاری خوبی با هم دارند و دارای تفکر ناب هستند، سریع تر به نتیجه خواهید رسید. برای اجرای این چارچوب، باید پیشرفت خود را در بازه های زمانی کوچک، با سرعت مناسب و به طور مستمر ارزیابی کنید. این قطعات می تواند iteration ها باشند.
این تمرین مهم است نه به این دلیل که CALMS باید به یک استاندارد تبدیل شود یا نه، به این دلیل که زمانی که جنبش های جدیدی به وجود می آیند (مانند جنبش DevOps)، باید مسیری از عادت به عملکرد فعالانه وجود داشته باشد. CALMS به کسانی که با Operations زندگی کرده اند و همچنین کسانی که حتی نمی دانند Operations چیست کمک می کند.
کسانی است که با ITSM آشنایی دارند ممکن است دچار این چالش ذهنی بشوند که تفاوت DevOps و ITSM چیست؟ آیا DevOps یک راهکار جایگزین برای ITSM است؟
اگر با مشاهده مثال ها و اسناد ITSM تفاوت ها به وضوح مشخص نبود، کلمه ی اختصاری CALMS در یک نگاه سریع به تشریح تفاوت های این روش ها کمک می کند. همانطور که مشاهده می کنید، فرهنگ اولین گام است، با مشاهده گزینه های بعدی، به سرعت مشخص می شود که نمی توان هیچ مقایسه ی مورد به موردی برای ITSM و DevOps داشت.
ITSM به طور کلی بر مستندسازی، کنترل تغییرات، و تکرارپذیری تمرکز دارد، در حالی که DevOps بر افرادی که این نتایج را بدیت می آورند تمرکز دارد. یک مولفه اصلی در ITSM، تکرارپذیر بودن است، اما ساختار و فرایند ها اهداف اصلی نیستند.

در این مطلب قصد دارم به استراتژی های پیشرفته ی استقرار نرم افزار که در Continuous Deployment و DevOps کاربرد فراوانی دارند، بپردازم. در پست قبلی به تعریف استراتژی و استراتژی استقرار نرم افزار پرداختیم، همچنین دو تا از استراتژی های پایه استقرار نرم افزار (Recreate Deployment و Rolling Deployment) را معرفی و بررسی کردیم.
Blue-Green Deployment یکی دیگر از استراتژی های استقرار است که به طور خلاصه شامل نگه داشتن همزمان دو نسخه از سرویس در محیط عملیاتی می شود که ریسک انتشار را به شدت کم می کند. نسخه قبلی (Blue) و نسخه ای که جدیدا منتشر شده و در دسترس قرار گرفته (Green). این روش معمولا از یک load balancer برای هدایت ترافیک به نسخه ی green می شود. اگر Monitoring یک رخداد (Incident) را شناسایی کرد، ترافیک به طور اتوماتیک به نسخه ی قبلی یعنی blue هدایت خواهد شد.
هدف Blue-Green Deployment ، حذف DownTime و کاهش ریسک های ناشی از Deployment وامکان Rollback بسیار سریع است.
روش انجام Blue-Green Deployment: در این روش علاوه بر محیط عملیاتی (سبز)، یک محیط کاملا مشابه اما جداگانه وجود دارد(آبی). نسخه ی قدیم اپلیکیشن در محیط سبز نصب شده و 100% از ترافیک عملیاتی به این محیط هدایت می شود. نسخه ی جدید اپلیکیشن روی محیط آبی نصب، راه اندازی و تست می شود، سپس در یک لحظه 100% از ترافیک عملیاتی به محیط آبی هدایت می شود. در این روش در هر زمان تنها یکی از نسخه ها عملیاتی است و نسخه ی دیگر غیر فعال است.
امکان Rollback در این روش بسیار سریع خواهد بود. همچنین قبل از عملیاتی شدن نسخه ی جدید برای کاربران، این فرصت ایجاد می شود تا از عملکرد صحیح اپلیکیشن و استقرار آن مطمئن شویم. بدین ترتیب ریسک حاصل از دیپلویمنت و نسخه ی جدید به شدت کم خواهد شد.
مثال: شکل زیر نشان دهنده ی این استراتژی به صورت کلی است.
مرحله اول: 100% ترافیک عملیاتی به محیط آبی که نسخه ی قدیمی در آن نصب شده هدایت می شود و نسخه ی جدید در محیط آبی نصب و راه اندازی می شود.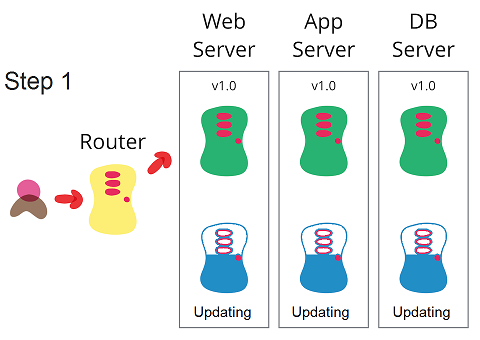
مرحله دوم: بعد از راه اندازی کامل نسخه ی جدید در محیط آبی، 100% ترافیک عملیاتی به محیط آبی هدایت می شود.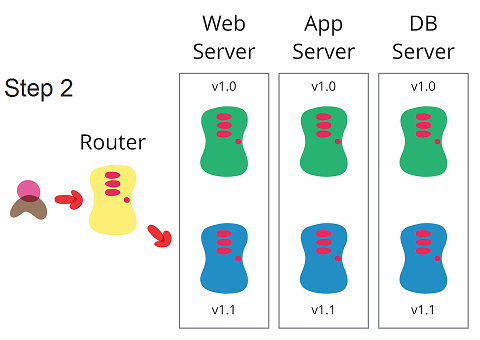
انتخاب این نام از داستان “قناری در معدن زغال سنگ” گرفته شده است. در گذشته معدنچیان با خود یک قناری در قفس به معدن می بردند، در چنین شرایطی اگر میزان گازهای سمی (متان یا مونو اکسید کربن) در معدن به حدی برسد که برای انسان خطر جدی ایجاد کند، قناری جان خود را از دست می داد و بدین ترتیب معدن چیان از وجود گازهای سمی باخبر می شدند.
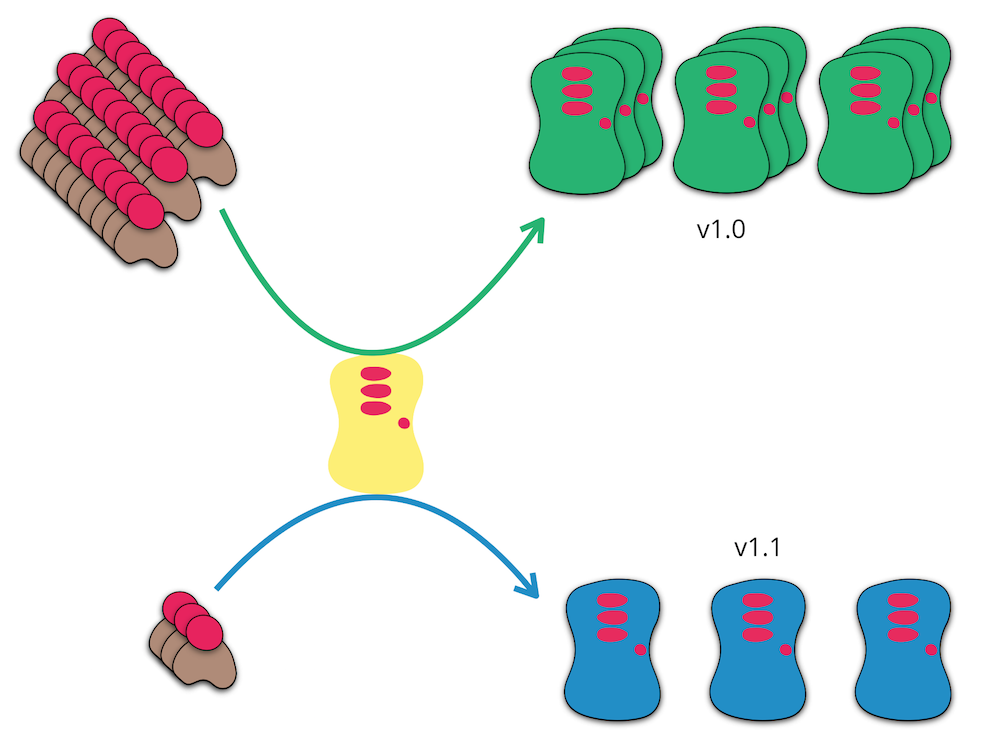
روش انجام Canary Deployment: در استراتژی استقرار به روش قناری، نسخه ی جدید اپلیکیشن روی تعداد کمی از نودهای عملیاتی منتشر می شود و درصد کمی از ترافیک عملیاتی به نسخه ی جدید هدایت می شود. در این روش دو نسخه قدیم و جدید به طور همزمان عملیاتی هستند. نسخه ی جدید، نقش یک قناری را بازی می کند تا بدون اینکه ریسکی متوجه اکثریت کاربران شود، متوجه شویم که وضعیت در عملیات چطور خواهد بود (از نظر integration با سایر اپلیکیشن ها، CPU، Mamory، disk Usage و …). در صورت رضایت بخش بودن می توان سایر نود ها را هم به روزرسانی کرد، در غیر اینصورت می توان تصمیم به fail کردن استقرار یا Rollback گرفت.
استراتژی قناری بر اساس این واقعیت به وجود آمده است که با وجود همه ی تست هایی که در محیط های قبلی انجام شده، باز هم ممکن است تعدادی باگ ها به عملیات منتقل شود. در این صورت و با استفاده از این روش، تعداد کمتری از کاربران با باگ مواجه می شوند و با دریافت سریع بازخوردها می توان تصمیم به Fail کردن استقرار یا Rollback گرفت تا برای اکثریت کاربران ریسکی ایجاد نشود.
Dark launching فرایندی است که در آن Featureهای جدید نرم افزار به نحوی تدریجی یا مخفیانه ریلیز می شود و در یک زمان مشخص، یا برای گروه های کاربری مشخصی، فعال و قابل استفاده می شود. با این روش می توان بازخورد بخشی از کاربران را دریافت کرد و در محیط عملیاتی بدون اینکه اکثر کاربران تحت تاثیر قرار گیرند، Performance Test انجام داد. با این روش دیگر نیازی نیست که انتشار Feature های تکمیل شده به دلیل یک یا چند Feature تکمیل نشده به تعویق بیافتد و می توان کدهای تکمیل نشده را (با در نظر گرفتن ملاحظاتی) بدون تاثیر در عملکرد کلی اپلیکیشن منتشر کرد.
روش انجام Dark Launch Strategy: این کار با به کارگیری یک تکنیک در توسعه نرم افزار به نام Feature Flag یا Feature Toggle انجام می شود. در این تکنیک، پیکربندی هایی برای هر Feature یا مجموعه ای از آن ها افزوده می شود، همچنین تکه کدهایی در ابتدای هر ویژگی استفاده می شود که با توجه به پیکربندی، آن ویژگی را در زمان خاصی، یا برای گروهی از کاربران فعال می کند.
Google، Facebook، و بسیاری از غول های فناوری اطلاعات برای ریلیز تدریجی و تست ویژگی های جدید توسط گروه کوچکی از کاربرانشان، از Dark Launching استفاده می کنند. بدین ترتیب قبل از ریلیز عمومی، این فرصت را پیدا می کنند تا میزان علاقه ی کاربران را شناسایی کنند و همچنین تاثیر تغییرات جدید را روی کارایی کل سیستم اندازه گیری کنند. ابزاری که Facebook برای این کار استفاده می کند، “Gatekeeper” نام دارد.
به این معنی است که دو (یا چند) نسخه مختلف از اپلیکیشن/کانفیگ به طور همزمان به منظور تست در حال اجرا باشند. آسان ترین راه استفاده از این روش، تقسیم ترافیک عملیاتی بین دو شاخه همگن (شاخه A و شاخه B) می باشد به طوری که در شاخه A، نسخه ی یکسانی از اپلیکیشن و کانفیگ ها وجود داشته (نسخه A) باشد و در نودهای شاخه ی دیگر، یک نسخه ی دیگر (نسخه B).
یک مثال پیچیده تر شامل یک proxy یا load-balancer تخصصی که ترافیک را بر اساس کاربران یا اپلیکیشن ها بین شاخه های A و B تقسیم می کند. تمامی تستر ها به شاخه B هدایت می شوند و سایر کاربران به شاخه A.
A/B Deployment می تواند به عنوان A/B Testing در نظر گرفته شود، اگر چه یک استقرار A/B نشان دهنده چندین نسخه از کد و پیکربندی است، در صورتی که A/B Testing اعلب از یک کد با چک های خاص برنامه تشکیل شده است.

