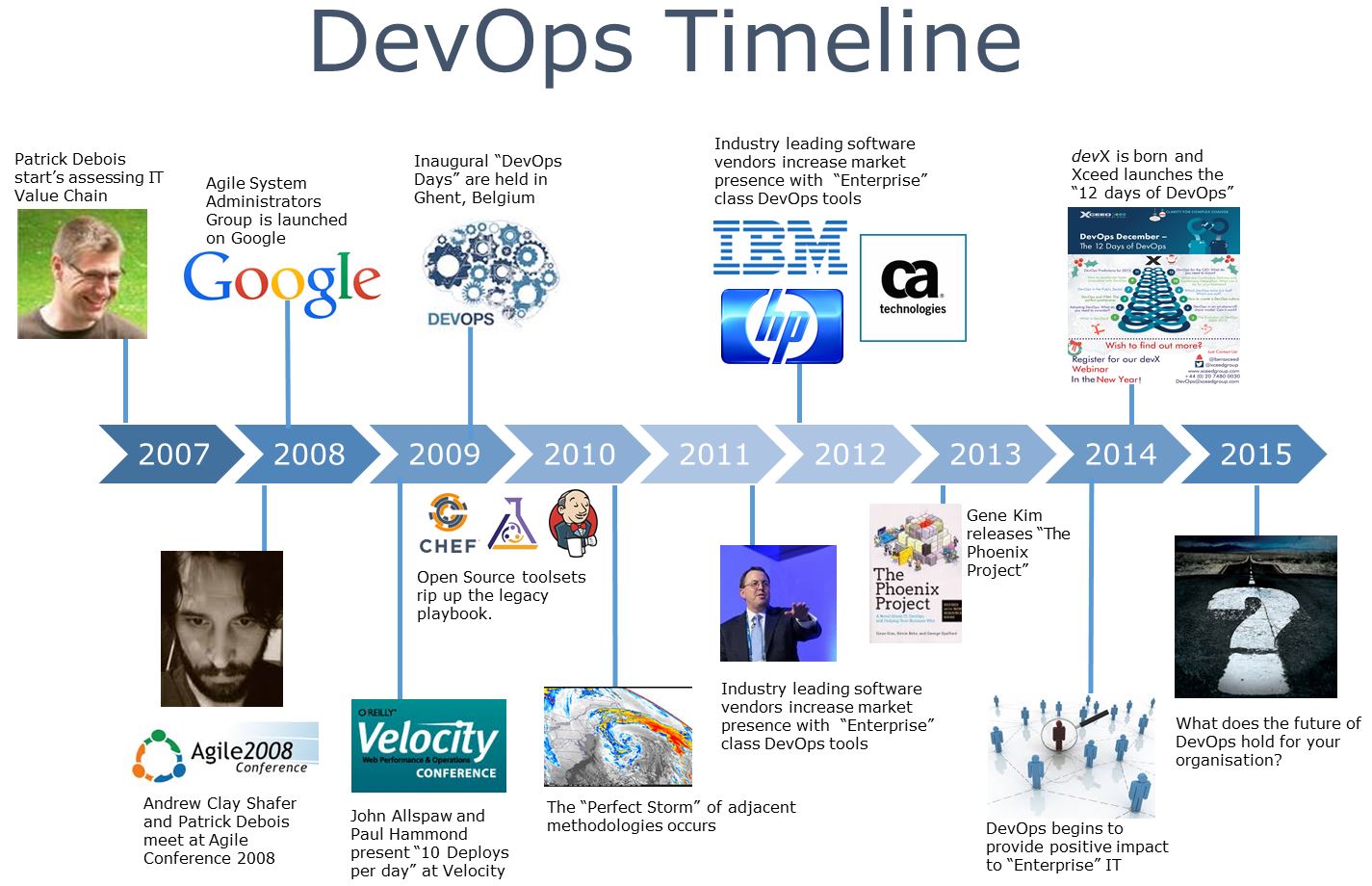
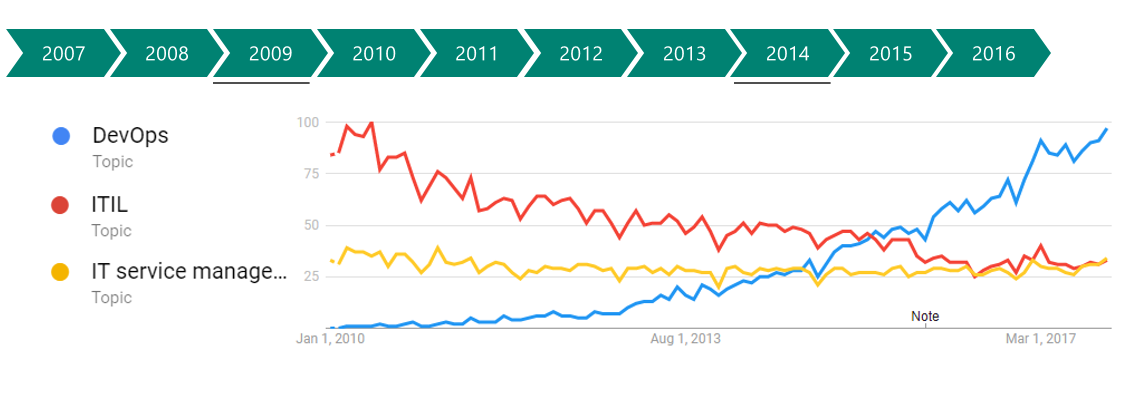
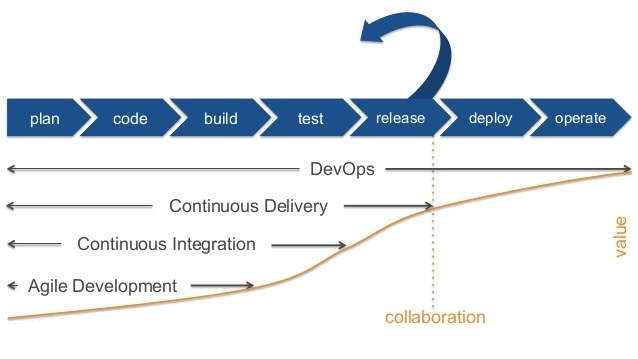
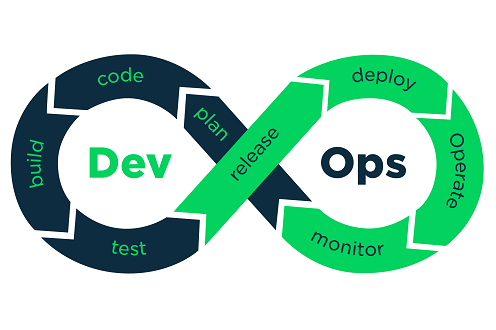
در این مصاحبه که در تابستان 2014 ضبط شده و در ابتدای سال 2015 منتشر شده است چارلز اندرسون با جیمز ترنبل ، در مورد Docker صحبت میکند. Docker یا داکر ابزاری است که با وجود عمر کوتاه خود، خصوصاً در محیطهای استقرار مستمر و در معماریهای مبتنی بر ریزسرویسها، توجه زیادی به خود جلب کرده است. جیمز ترنبل یک نویسنده مستقل نرمافزارهای متنباز، متخصص امنیت و توسعهدهنده نرمافزار است. او نایبرییس شرکت Docker است. او نقشهای مشابهی در PuppetLabs و Venmo داشته است. همچنین کتابهایی در مورد Docker ، Puppet ، Logstash ، مدیریت سیستمهای لینوکس و امنیت نوشته است.
منبع: www.se-radio.net
ترجمه: www.se-topics.ir
جیمز، به SE Radio خوش آمدید.
ممنون، خوشحالم که اینجا هستم.
خیلی سطح بالا و بصورت خلاصه، داکر یا Docker چیست؟
داکر یک تکنولوژی مجازیسازی محفظه (Container Virtualization) است. مانند یک ماشین مجازی خیلی سبک است.
علاوه بر ساختن محفظهها ما چیزی که آن را جریان کاری توسعهدهنده (Developer Workflow) مینامیم را نیز فراهم میکنیم که در واقع درباره کمک کردن به افراد برای ساختن محفظهها و تولید برنامهها داخل محفظهها و بعد، به اشتراک گذاشتن آنها در بین همتیمیهایشان است.
بسیار خوب، چه مسألهای را حل میکند؟
چند مسأله را بطور خاص میتوانیم مطرح کنیم.
اول اینکه ماشین مجازی، به نسبت، منبع محاسباتی سنگینی است. هر ماشین مجازی یک کپی از سیستمعامل است که بر روی Hypervisor اجرا میشود که آن نیز خود بر روی سختافزار فیزیکی اجرا میشود و برنامه کاربردی بر روی همه آنها اجرا میشود. این باعث چالشهایی در مورد سرعت و کارایی و مشکلاتی در محیطهای چابک شده است. ما قصد داشتیم این مشکل را برطرف کرده و یک چیز سبکتر و یک منبع محاسباتی چابکتر، تولید کنیم. اغلب، محفظههای Docker در کسری از ثانیه بالا میآیند و Hypervisorای وجود ندارد که سیستم بر روی آن اجرا شده باشد. شما میتوانید تعداد زیادی از آنها را بر روی یک ماشین فیزیکی یا ماشین مجازی قرار دهید. بنابراین، مقیاسپذیری خوبی خواهید داشت.
مشکل دومی که میخواهیم به آن نگاهی بیاندازیم این است که ما متوجه این مسئله شدهایم که برای اغلب افراد، مهمترین دارایی IT، همان کدهایی است که توسعه میدهند و این کد بر روی ایستگاههای کاری (Workstation) توسعهدهندهها یا لپتاپهایشان یا محیط DevOps قرار گرفته است اما این کدها تا زمانی که به دست مشتری نرسد برای شرکت، هیچ ارزشی تولید نکرده است. و رویهای که به دست مشتری برسد یک جریان کاری شامل توسعه، تست، قرارگرفتن در سکو و استقرار در محیط عملیاتی است که یکی از پراصطکاکترین کارها در IT است. به عنوان مثال کل جریان DevOps از این حقیقت و مشکل کلاسیک در بسیاری از سازمانهای معظم IT نشأت گرفت که توسعهدهندهها برنامهها را توسعه میدادند و به تیم عملیات میدادند اما آنها متوجه میشدند که آن برنامهها در محیط عملیاتی اجرا نمیشوند. همان مشکل کلاسیک که بر روی ماشین من اجرا میشود اما تیم عملیات با آن مشکل دارد!
بنابراین ما قصد داریم که یک تکنولوژی سبک محاسباتی بسازیم که کمک کند افراد کدها و برنامههایشان را داخل منابع محاسباتیشان (Computing Resource) قرار داده و مجموع آنها قابل انتقال به گروه تست و عملیات باشند و همهاش در محیط عملیاتی قابل نمونهسازی باشد با این فرض که آنچه میسازید و اجرایش میکنید و تستش میکنید همان چیزی است که در محیط عملیاتی اجرا خواهید کرد.
بسیار خوب، ما بعداً برخی جزییات را مطرح میکنیم اما اکنون بگویید که چه موارد کاربرد خوب یا مرسومی برای یک توسعهدهنده یا مدیرسیستم برای استفاده از Docker وجود دارد؟
چندین مورد کاربرد واقعاً جدی دارد. مورد اول، کاربرد در دنیای یکپارچهسازی مستمر (Continuous Integration) و استقرار مستمر (Continuous Deployment) است. Docker خیلی سبک است که به این معناست که توسعهدهندههای زیادی داریم که پشتههایی از محفظههای Docker را بر روی لپتاپهایشان ایجاد میکنند و کپیهایی از محیط عملیاتی میسازند مثلاً LAMP Stack و محیطهای چندلایهای [را میسازند]. آنها میتوانند برنامهشان را بر روی این پشته (Stack) تولید و اجرا کنند که به این معناست که خیالشان کاملاً راحت است که آنچه اجرا میکنند مانند محیط عملیاتی است و بعد تستها را اجرا میکنند و تست پذیرش مشابه با محیط عملیاتی خواهد بود. از آنجاییکه بعداً میتوانید این محفظهها را جابجا کنید و قابل انتقال هستند، بعداً میتوانید در محیطهای استقرار مستمر، خیلی سریعتر کار کنید. مثلاً فرض کنیم که یک محیط استقرار مستمرِ Jenkins دارید، در این حالت به ماشینهای مجازی متکی بوده و مجبوریم که ماشینهای مجازی را بسازیم و همه نرمافزارها را نصب کرده و برنامه و کدها را نصب کرده و بعد تستها را اجرا کنیم و بعد دوباره همهی آنها را پاکسازی کنید چرا که ممکن است فرآیند تست، وضعیت VM را خراب کرده باشد و مجبور شویم این چرخه را تکرار کنیم. شاید در این فرآیند CI (مخفف Continuous Integration)، ساختن این ماشینهای مجازی 10 دقیقه طول بکشد اما درعوض، در دنیای Docker این ماشینهای مجازی یا اصطلاحاً محفظهها را در چندثانیه میسازید که به این معناست که فرآیند تولید و تست شما، 10 دقیقه کوتاه میشود که یک صرفهجویی شگفتانگیز در هزینه است. شما به سرعت، تعدادی محفظه میسازید و بعد تستهایتان را اجرا میکنید و براساس نتایج تست ممکن است به انجام تغییراتی و تکرار فرآیند تست نیاز داشته باشید.
مورد دیگر، چیزی است که ما به نوعی آن را ظرفیت بالا مینامیم؛ ماشینهای مجازی سنتی، Hypervisor دارند. Hypervisor، ده تا پانزده درصد ظرفیت (ماشینِ) میزبان را میگیرد. خیلی از مشتریها هستند که برایشان ده تا پانزده درصد خیلی پرهزینه است و تصمیم میگیرند آن را کنار گذاشته و با یک میزبان Docker جایگزینش کنند تا بتوانند محفظههای خیلی بیشتری اجرا کنند و مقیاس بالایی از محفظهها را بر روی یک میزبان راه بیاندارند. بعلت فقدان Hypervisor و اینکه محفظهها مستقیماً بر روی سیستمعامل قرار میگیرند، خیلی خیلی سریع هستند. سال گذشته تحقیقاتی انجام شد که نشان داد در سیستمهای مبتنی بر تراکنش، بطور متوسط محفظهها، 25% سریعتر از یک ماشین مجازی عمل میکنند که کاملاً شگفتانگیز است.
——————————————————————————————
بله، شگفتانگیز است. Docker توسعه را سریعتر (به قول شما چابکتر) میکند و وقتی به مرحله عملیات برسد، تأثیرش بیشتر هم خواهد شد.
بله.
بسیار خوب. بیایید کمی در این مورد عمیقتر شویم که Docker کارهایش را چگونه انجام میدهد.
Docker مبتنی بر محفظه است. محفظهها، محیطهای ایزوله برای کدهای مُد کاربر (User Mode) فراهم میکنند. برخی از شنوندگان ما احتمالاً با سیستمهای محفظهای قدیمیتر از قبیل Solaris Zones و یا FreeBSD Jails یا حتی اگر عقبتر برویم از نسخه 7 یونیکس به بعد با فراخوانی سیستمی chroot ، آشنا هستند. کدی که در یک محفظه اجرا میشود، فایلسیستم ایزوله خود را دارد و تنها میتواند پروسسهای در همان محفظه را ببیند.
بدون رونوشت گرفتن ازفایلسیستم برای محفظههای یکسان، چگونه هر محفظه کپی خود از فایل سیستم را خواهد داشت؟ خصوصاً اینکه شما در مورد مقیاسپذیری فوقالعاده صحبت میکنید.
یکی از تکنولوژیهای دیگر که Docker به آن متکی است، مفهومی است که ما به آن کپی کردن به هنگام نوشتن (Copy on Write) میگوییم. فایلسیستمهای متعددی هستند که این قابلیت را فراهم میکنند. Btrfs ، AUFS و نگاشتگرهای Device، عملکردی دارند که تدارکات سبک (Thin Provisioning) نامیده میشود، ویژگی مشترک همه آنها نوعی از مدل کپی کردن به هنگام نوشتن است. همان چیزی که توسعهدهندههای کرنل به آن فایلسیستم مجتمع (Union File System) میگویند. آنچه رخ میدهد این است که لایههایی از فایلسیستم را میسازید. هر محفظه Docker بر روی چیزی که ما آن را تصویر (Image) مینامیم ساخته میشود. تصویرهای Docker همانند فایلسیستمهای از پیشساخته هستند. آنها شامل لایه نازکی از کتابخانهها و فایلهای اجرایی هستند که برای به کار انداختن برنامه مورد نیاز است. احتمالاً هر برنامهای، نیاز به تعدادی پکیجهای پشتیبان دارد مثلاً ممکن است LAMP Stack را نیاز داشته باشد یا سرور Apache یا … . این تصویر، بر روی اصطلاحاً لایه خودش (لایه فایلسیستم) ذخیره میشود. اگر بخواهیم تغییری بر روی این تصویر ایجاد کنیم مثلاً پکیج دیگری را نصب کنیم فرضاً سیستم را بوت کرده و بخواهیم PHP را نصب کنیم و فرمان apt-get install php را بزنیم، آنچه Docker انجام میدهد این است که یک لایه بر روی لایه موجود میسازد و فقط چیزهایی که تغییر کردهاند را در آن اضافه میکند یعنی در اینجا فقط همین پکیج را اضافه میکند.
این تولید لایه به لایه به این معنی است که به یک فایلسیستم فقط خواندنی (Read Only) میرسیم که شامل لایههای مختلفی است. میتوانید آنها را مانند کامیتهای Git (یا هر ابزار کنترل کد دیگر) در نظر بگیرید. در نتیجه، به یک سیستم خیلی سبک میرسیم که تنها، چیزهایی که میخواهیم بر روی آن قرار دارد و وقتی به عنوان مثال میخواهیم آنها را دوباره بسازیم، Docker میفهمد که من از قبل PHP را نصب کردهام و قرار نیست تغییری بر روی این محیط ایجاد کنم و قرار نیست چیزی بنویسم و فقط میخواهم چیزهای موجود در لایه PHP را استفاده کنم. بعنوان مثال اگر تغییری در سورسکدهای خود بدهید، برخلاف کاری که برای ماشین مجازی میکردید که یک ماشین مجازی میساختید، در اینجا Docker تغییراتی که قرار است در سورسکدها انجام شود را به تصویر (Image) میافزاید که شاید مثلاً تنها 10 کیلوبایت باشد، بنابراین Docker فقط همان چیزهایی که قرار است تغییر کند را درفایلسیستم مینویسد. در نتیجه خیلی سبک است و واقعاً خیلی سریع ساخته میشود و با کش کردن، دوبارهسازی آن نیز فوقالعاده سریع خواهد بود.
بسیار خوب، لایهها کمی مانند تصاویر مقطعی (Snapshot) در ماشینهای مجازی هستند.
بله، خیلی مشابه آنها هستند با این تفاوت که بخاطر ماهیت فقط خواندنی خود، احتمالاً منعطفتر از آنها هستند، اگر شما یک تصویر مقطعی را دوباره بکار بگیرید تضمینی وجود ندارد که در همان وضعیت اجرایی (Running State) قرار بگیرد؛ کتابخانهها و فایلهای اجرایی در آنها فقط وضعیتهای داخل حافظه نیستند بلکه [بر روی] فایلسیستم هستند. اما یکی از فایلسیستمهایی که ما استفاده میکنیم، نگاشتگر Device است، ما از قابلیت تدارکات سبک (Thin Provisioning) استفاده میکنیم که بصورت منطقی یک ابزار برای گرفتن تصاویر مقطعی را طراحی میکند.
بسیار خوب، من همینطور اشاره کردم که پروسسهای داخل یک محفظه فقط میتوانند پروسسهای داخل همان محفظه را ببینند. توضیح دهید این چطور کار میکند؟
Docker به شدت متکی به دو مورد از تکنولوژیهای کرنل لینوکس است. اولی، فضای نام (Namespace) خوانده میشود. فرض کنید شما پروسس جدیدی در کرنل لینوکس اجرا میکنید. در اینصورت شما یک فراخوانی سیستمی به فضای نام پروسسها میکنید که میخواهید یک پروسس جدید بسازید، همینطور اگر بخواهید یک واسط شبکه جدید بسازید یک فراخوانی به فضای نام شبکه میکنید و کرنل فضای نام خودتان را تخصیص میدهد که پروسس و همه منابع دیگری که خواستهاید مثلاً دسترسی به شبکه، دسترسی به بخشهایی ازفایلسیستم و دسترسی به حافظه یا CPU را در خود دارد.
وقتی ما یک محفظه Docker میسازیم، تعدادی فراخوانی به کرنل لینوکس داریم که بدینوسیله از آن میخواهیم که یک جعبه (Box) برایمان بسازد و میخواهیم که آن جعبه دسترسی به فایل سیستم مشخصی، دسترسی به حافظه و CPU، دسترسی به شبکه را داشته باشد و بایست داخل فضای نام همین پروسس باشد. شما کاملاً درست گفتید، در داخل این فضای نام نمیتوانید هیچ فضای نام پروسسی که خارج از آن قرار گرفته را مشاهده کنید.
تکنولوژی دیگری که بکار گرفتهایم گروههای کنترلی یا CGroup ها هستند. گروههای کنترلی به عنوان مثال به شما این امکان را میدهد که بگویید فلان محفظه ، فقط 120 مگابایت از RAM را داشته باشد یا فلان محفظه دسترسی به شبکه نداشته باشد. شما میتوانید بر اساس نیاز این قابلیتها را اضافه و حذف کنید. این خیلی قدررتمند است از این جهت که میتوانید کنترل دقیقی بر روی محفظهها به همان طریقی که در واسط VMware دارید، داشته باشید که بگویید فلان کارت شبکه را بگیر، فلان هسته CPU را بگیر، فلان حافظه و دسترسی به فلان فایلسیستم مربوط به CD_ROM مجازی را داشته باش و … . سطح یکسانی از تکنولوژی را دارد.
محفظهها به غیر از فایلها و پروسسها، محیط ایزولهای برای آدرسهای شبکه و پورتها نیز فراهم میکنند. به عنوان مثال میتوانیم وبسرورهایی بر روی چندین محفظه در حال اجرا داشته باشیم که همگی از پورت 80 استفاده کنند. به صورت پیشفرض، پورتهای شبکه یک محفظه، در معرض خارج از آن (محفظه) قرار نمیگیرند اما به صورت دستی یا عامدانه میتوان آنها را عرضه کرد. این کار کمی مشابه با باز کردن پورتهای یک جدول IP بر روی یک فایروال است. درست است؟
بله، آنچه رخ میدهد به این صورت است که هر شبکه، واسط شبکه خود را دارد که یک واسط مجازی شبکه است. شما میتوانید داخل هر محفظه پروسسهایی را اجرا کنید که به پورتهای داخل آن محفظه دسترسی داشته باشند. به عنوان مثال میتوانم 10 محفظه Apache داشته باشم که داخل هرکدام یک سرویس بر روی پورت 80 اجرا شده باشد، همینطور میتوانم این پورتها را به خارج از محفظه عرضه کنم. اگر بخواهم میتوانم پورت 80 (داخل محفظه) را روی پورت 80 (خارج از محفظه) عرضه کنم که میتوانم یک بار (برای یکی از آنها) این کار را بکنم اما به صورت پیشفرض، کاری که Docker انجام میدهد این است که یک پورت تصادفی با شماره بالا را انتخاب میکند مثلاً پورت 80 داخل محفظه را روی پورت 49154 سیستم میزبان عرضه میکند. بنابراین پروسسهای Apache ام بر روی پورتهای مختلف اجرا خواهند شد و بعد میتوانم یک ابزار کشف سرویس (Service Discovery Tool) یا یک تعدیلکننده بار (Load Balancer) یا نوعی پروکسی را جلوی آن قرار دهم. HAProxy خیلی متداول است، برخیها هم از nginx استفاده میکنند. برخی ابزارهای کشف سرویس از قبیل ZooKeeper و Etcd و Consul نیز استفاده میشود.
این قابلیت را میدهد که بتوانید بگویید من میخواهم فلان برنامه (جهت یافتن سرویس مورد نظر خود) از آن برنامه خاص کشف سرویس پرس و جو کند و اینکه مثلاً پروسس Apache به آن 10 محفظه تعلق داشته باشد و بتوانید یکی از آن 10 پورت را برای اتصال به پروسس Apache انتخاب کنید. بنابراین یک مدل کاملاً منعطف و مقیاسپذیری وجود دارد که برای اجرای برنامههای پیچیده طراحی شده است.
بسیار خوب، Docker همینطور امکان برقرار کردن اتصال بین محفظهها را هم فرآورده میکند. برای مثال میتوانم یک سرور Apache داشته باشم و یک سرور برنامههای جاوا (Java Application Server) داشته باشم و بین آنها اتصال برقرار کنم. درست است؟
درست است. چون که Docker بصورت پیشفرض، بسته است زیرا ما فکر میکنیم امنترین راهش این است که شما کسی باشید که تصمیم بگیرید کدام پورتها به معرض گذاشته شوند. بعنوان مثال انواع مختلفی از محفظهها مثلاً محفظههای پایگاه داده و محفظههای سرورهای برنامه (Application Server) هستند که هیچگاه نباید در معرض مشتری قرار بگیرند و تنها باید در معرض محفظههایی قرار بگیرند که منابعشان را مصرف میکنند.
به عنوان مثال میتوانم یک محفظه پایگاه داده را اجرا کرده و به آن یک اسم بدهم مثلاً میتوانم آن را پایگاه داده MySQL شماره 1 بنامم و بعد میتوانم یک محفظه وب هم راه بیاندازم، در این حالت کاری که باید بکنید این است که (از محفظه وب) به آن (محفظه پایگاه داده MySQL شماره 1) لینک بزنید که به این معنی است که بر روی یک پورت خاص، یک تونل رمزگذاری شده بین محفظه وب و محفظه پایگاه داده مقصد ایجاد کنید و اطلاعاتی در داخل محفظه خود فراهم کنید به این ترتیب که تعدادی مدخلهای میزبان DNS و تعدادی متغیرهای محیطی (Environment Variable) در محفظه مورد نظر ایجاد میشود تا برنامه از آنها استفاده کرده و بفهمد که پایگاه داده کجا قرار گرفته است. بنابراین آدرس IP که ممکن است آن را ندانید را هاردکد نخواهید کرد و بعد از آن، آنچه رخ میدهد این است که اکنون محفظه پایگاه داده و محفظه وب با هم اتصال دارند. فقط آنها میتوانند با هم صحبت کنند، شما نمیتوانید پایگاه داده را پینگ کنید یا جستجویش کنید مگر آنکه همان محفظهای باشید که روی پورت خاص با آن صحبت میکنید.
بنابراین یک راه خیلی ساده برای تولید پشته برنامهها و برنامههای سبکِ مانند این وجود دارد. این کارهای خیلی ابتدایی است که ما آن را Links نسخه اول مینامیم و در نسخههای بعدی Links، مفاهیم خیلی دینامیکتری خواهیم داشت فرضاً اینکه هنگام رخداد خرابی بصورت خودکار، بروزرسانی داشته باشیم مثلاً وقتی که یک پایگاه داده که بر روی یک مرکز داده قرار دارد خراب شود، محفظه وب بصورت خودکار، لینک دوم را بشناسد که ممکن است یک محفظه پایگاه داده دیگر در یک مرکز داده دیگر باشد. اموری از این قبیل در نقشه راه قرار گرفته است که باعث میشود این تکنولوژی واقعاً جذاب شود.
بله، این قطعاً راحتتر و کمی سطح بالاتر از سوار شدن بر روی یک IP و پورت خاص است.
Docker به دنیا به شکل معماری خیلی سرویسگرایی مینگرد. ما به شدت درگیر دیدگاه SOA یا سرویسگرا از دنیا هستیم که بر طبق آن، نباید درباره چیزهایی مانند آدرس IP و پورت نگران باشید، بلکه باید بتوانید سرویسها را خطاب قرار دهید، باید بتوانید بگویید که «من میدانم که سرویسی با نام MySQL وجود دارد و این برنامه میخواهد از آن استفاده کند. من میخواهم که زیرساختها، به جزییات این کار رسیدگی کنند. من نباید مجبور باشم که به سراغ کسی بروم تا یک قاعده بر روی فایروال برایم ایجاد کند یا یک پورت را برایم باز کند و … . سرویس من باید بتواند با سرویسهای دیگر صحبت کند و کنترل مطلوب و سطح دسترسی مطلوب را داشته باشد»
بله، کاملاً منطقی است.
بصورت پیشفرض، حافظه ذخیرهسازی محفظهها، موقتی هستند و وقتی محفظه از بین میرود حافظه ذخیرهسازی هم از بین میرود. فضاها (Docker Volume) مکانیزمی برای داشتن حافظه ذخیرهسازی پایا و به اشتراک گذاری بین محفظهها ایجاد میکنند. ممکن است در این مورد توضیح دهید.
قبلاً در مورد تصویر محفظه (Container Image) و لایهها (Layers) صحبت کردیم. وقتی یک محفظه را اجرا میکنید، یک لایه دیگر بر روی آن میسازید که یک لایه با حق دسترسی فقط خواندن است و تا زمانی که کاری برای ذخیرهسازی این اطلاعات نکنید، ناپایا (Ephemeral) هستند و وقتی از محفظه خارج میشوید، از بین میروند.
در اینجا ما مفهوم Volume را داریم. آنها خودشان بخشی از فایلسیستم هستند. آنها تا حدودی مانند آدرسهای سوارشده (Mounted) هستند. شما میتوانید یک محفظه بسازید و بخشی از آن محفظه را بصورت Volume در دسترس قرار دهید. یک مثال کلاسیکش میتواند این باشد که یک محفظه Apache اجرا کنید و یک Volume بر روی فلان دایرکتوریاش، سوار کنید و داخل آن، سورس کد برنامهتان را داشته باشید.
دو نوع Volume می توان ایجاد کرد: یکی اینکه از روی فایلسیستم دستگاه میزبان نگاشت را انجام دهید. به عنوان مثال میتوانید بگویید که در سیستم میزبان به فلان دایرکتوری رفته و آن را بر روی محفظه من نگاشت کن. با این روش میتوان سورسکد را بر روی یک مخزن (Repository) نگاه داشت و محفظه را بر روی آن اجرا نمود. این بدان معناست که وقتی تغییری بر روی کد انجام دهم میتوانم به محفظه رفته و تغییرات را در آنجا ببینم.
نوع دوم Volume به این روش است که میتوانید بین محفظهها اشتراک بگذارید. مثالش میتواند این باشد که یک محفظه پایگاه داده داشته باشید و دایرکتوری MySQL را بعنوان یک Volume در دسترس قرار دهید و آن زمان، محفظه دیگری را اجرا کنید و آن Volume را برروی آن سوار کنید. به عنوان مثال ممکن است بخواهید نسخهبرداری (Replication) یا پشتیبانگیری (Backup) یا ذخیره لاگ یا کارهای مشابه آن داشته باشید. برای این منظور محفظه MySQL را اجرا کرده و سپس به عنوان مثال یک محفظه پشتیبانگیری را اجرا میکنم که Volume حاوی دایرکتوری MySQL بر رویش سوار شده است و بنابراین قادر خواهم بود که از دادههای آن پایگاه داده نسخه پشتیبان گرفته، و جایی داخل محفظه ذخیره کنم.
به این ترتیب قادر خواهید بود که برنامههای چندردهای (Multi-tier) و چندسکویی (Multi-stage) داشته باشید. ما خیلی روی این موضوع تمرکز داریم که هر محفظه واقعاً یک کار انجام دهد مثلاً یک محفظه، یک پروسس وب را اجرا کند یا سرور برنامههای وب را اجرا کند یا پشتیبانگیری کند یا لاگ بزند و … که همان مدل معماری سرویسگرای ریزسرویسها است.
ما در مورد اینکه محفظهها از تصویرها ساخته و اجرا میشوند صحبت کردیم. شما یک کمی به این مقدمات اشاره داشتید که تصویرها لایه به لایه ساخته میشوند. ممکن است کمی در این مورد صحبت کنید که چطور تصویرها را میسازیم؟
قطعاً. تصاویر Docker بصورت کلی از چیزهایی که Dockerfile خوانده میشوند ساخته میشوند. یک Dockerfile ، لیستی از دستورها است که برای تولید تصویر، اجرا میشود. هر تصویر Docker از یک تصویر که ما آن را تصویر مبنا (Base Image) مینامیم آغاز میشود. تصویر مبنا همان چیزی است که من در موردش صحبت کردم و یک پوسته خیلی نازک از فایلهای کتابخانهای و اجرایی است که چیزی مشابه با یک سیستمعامل را میسازد. یک تصویر مبنا میتواند چیزی مانند Ubuntu باشد. ممکن است بر مبنای نسخه خاص 14.04 از Ubuntu باشد و شامل مینیمم امکانات سیستمعامل Ubuntu باشد که برای اجرا و تعامل با کرنل و انجام کارهای ابتدایی لازم است. بعنوان مثال شامل libc و ابزار apt-get برای مدیریت پکیج و ابزارهای مدیریت سیستم از قبیل systemd و چیزهای مشابه آن است. اما شامل چیزهایی از قبیل vim (ابزار ویرایش متن) و X (کتابخانههای گرافیکی) و … نیست. تنها شامل حداقلهای مورد نیاز برای اجرای سیستمعامل است. میتوان آن را یک ساختار حداقلی و لاغر در نظر بگیرید. در مقایسه با ماشینهای مجازی که چند گیگابایت حجم دارند، اینها غالباً خیلی سبک هستند مثلاً ما یک تصویر مبنای Docker داریم که مبتنی بر یک توزیع BusyBox از لینوکس است که فوقالعاده کوچک است و حدود 24 مگابایت حجم دارد. تصور کنید که فرضاً بتوانید LAMP Stack را بر روی سیستمعاملی که 24 مگابایت حجم دارد اجرا کنید! از لحاظ سرعت و حجم، خیلی شگفتانگیز است.
بر روی تصویر مبنا فرضاً بر روی تصویر مبنایی که Ubunto 14.04 باشد، میتوانم چندین گام ساخت (Build Step) داشته باشم. به عنوان مثال این گامها میتواند شامل این باشد که: « Apache را نصب کن» یا میتواند این باشد که: «برخی کدهای برنامه یا فایلهای پیکربندی را داخل تصویر، اضافه کن» و بعد میتواند اعمال تنظیماتی از این قبیل باشد که: «دایرکتوری جاری (Working Directory) داخل تصویر را مقداردهی کن یا کاربری که باید برنامهها با آن Run as شوند را تنظیم کن» و بعد احتمالاً مقداری تنظیمات شبکه خواهید داشت مثلاً اینکه: «این تصویر باید پورت شماره 80 را به معرض بگذارد». در نهایت، هنگامیکه میخواهیم محفظه را از روی تصویر اجرا کنیم خواهیم گفت که برنامه پیشفرضی که باید در محفظه اجرا شود کدام است، در مثال Apache احتمالاً خواهم گفت که اجرای Apache Daemon کار پیشفرضی است که باید انجام بدهی!
بنابراین، ابتدا یک دستور با عنوان docker build را اجرا میکنیم که یک Dockerfile را میگیرد و دستورات داخل آن را اجرا کرده و در انتها، چیزی را به شما میدهد که ما به آن تصویر میگوییم و تصویر، یک مشخصه (Identifier) دارد که یک رشته بلند شبیه SHA است و در عین حال میتوانید به آن یک نام هم بدهید. مثلاً میتوانم اسم آن را jamesturnbull/apache بگذارم. این [روش نامگذاری] کاملاً مشابه با نگرشی است که Git هم دارد که اول نام کاربر مالک میآید و بعد نامی که میخواهیم به مخزن (Repository) بدهیم که در اینجا apache است.
بعد میتوانم یک دستور دیگر را اجرا کنم که docker run نامیده میشود و تصویر jamesturnbull/apache را برایش مشخص کنم تا وب سرور Apache را از آن تصویر راهاندازی کند. و اگر بخواهم تغییری در آن بدهم، آن را متوقف کرده و دوباره docker build را اجرا میکنم و از آنجاییکه همه چیز Cache میشود، تنها تغییرات مورد نیاز ذخیره میشود.
خود تصاویر میتوانند از طریق DockerHub به اشتراک گذاشته شوند و هم شرکتی که اطلاعات محرمانه دارد، میتواند مخزن داخلی خودش را راه بیاندازد. درست است؟
بله، یکی از موارد واقعاً جذابی که در موردش صحبت کردم، قابلیت انتقال است. تصاویر Docker را براحتی میتوان منتقل کرد. ما یک محصول نرمافزار به عنوان سرویس (Software as a Service) با عنوان DockerHub داریم که خیلی مشابه با Git Hub است با این تفاوت که برای تصاویر Docker است. یک نسخه اختصاصی آن را هم داریم که آن هم متن باز است و مشابه با Git Hub Enterprise است و پشت فایروال قرار میگیرد.
بنابراین یکی از رویههای مرسوم میتواند این باشد که یک توسعهدهنده در تیم یک تصویر برای نرمافزارش بسازد و تستش کند، آنگاه برای اینکه آن را با دیگر اعضاء تیم به اشتراک بگذارد با دستور docker push و ذکر نام تصویر مورد نظر آن را به DockerHub بفرستد. DockerHub همانند Git Hub، مخزنهای خصوصی هم دارد و اگر بخواهید آن را برای همگان به اشتراک نگذارید میتوانید تیمی از افرادی داشته باشید که به آن مخزن خصوصی دسترسی داشته باشند. آنگاه میتوانید به دیگر اعضاء تیم بگویید که یک تصویر جدید آماده شده است و اعضاء دیگر تیم، با دستور docker pull همانند کاری که در Git Hub میکنند تصویر جدید را بردارند.
از آنجاییکه اینجا نیز از مکانیزم کپی به هنگام نوشتن (Copy on Write) استفاده میشود و Cache میشود تنها، تغییراتی که برای بروزرسانی تصویر شما به نسخه آخر مورد نیاز است را میآورد. مدت زیادی برای بروزرسانی طول نمیکشد و حجم زیادی از فضای دیسک شما را نمیگیرد. همه اعضاء تیم بر روی یک تصویر یکسان کار میکنند که فوقالعاده است چرا که یکی از مشکلات کلاسیک در محیطهای توسعه نرمافزار این است که وقتی افراد جدید به شرکت میپیوندند، باید یک محیط پاک و مناسب تحویل بگیرند اما به علت آشفتگیهایی که وجود دارد و تغییراتی که رخ میدهد، در نهایت به 4-5 نفر در تیم میرسید که هر کدام محیط توسعه متفاوتی دارند! مثلاً وقتی بیل به تیم ملحق شده ما یک نسخه از JVM را داشتهایم و او اخیراً نسخه James را بروزرسانی نکرده و وقتی جیم به تیم ملحق شده نسخه JVM متفاوتی را استفاده میکردهایم و … . [اما با استفاده از محفظهها] از این مشکلات اجتناب میکنید زیرا میتوانید خیلی سریع و راحت توزیع داشته باشید و لازم نیست که کل یک ماشین مجازی را توزیع کنید یا حتی یک اسکریپت Build را اجرا کنید، یا اینکه حتی تصویر ماشین مجازی را داخل فلش گذاشته و با آن در اتاقها چرخ بزنید، من واقعاً اگر ببینم که هنوز هم کسی چنین کاری را میکند شوکه میشوم اما اینها، واقعاً رخ میدهد.
شما قصد مقایسه با Git Hub را داشتید. اگر بگوییم که محفظهها، ماشینهای مجازی سبک هستند آنگاه DockerHub ، روشی برای به اشتراک گذاشتن، بهبود دادن و استفاده کردن از این ماشینهای مجازی است همانطور که با Git Hub همین کارها را با سورسکدها میکنیم.
محفظهها، ماشینهای مجازی خیلی سبکی هستند. آنها نوع دیگری از ماشینهای مجازی هستند و برای مجازیسازی بیشتر به سیستمعامل تکیه دارند با این وجود، همچنان نوعی ماشین مجازی هستند. بله، DockerHub و تمامی ابزارهای Docker برای این طراحی شدهاند که رویهی به اشتراکگذاری منابع کامپیوتری را تسریع کنیم. به جای اینکه مجبور باشیم که برای ماشین مجازی یا مثلاً یک نمونه سرویس ابری منتظر شویم، اگر بتوانیم زمان راهاندازی را به کسری از ثانیه برسانیم و زمان تولید را بطور شگفتآوری سریع کنیم و انتشار تصویر تولیدشده کاملاً ساده و ارزان باشد، در آن صورت خیلی از سختیهای کارهای توسعهدهندهها کاسته میشود، دیگر نیاز نیست به سراغ مدیرسیستم بروند و یک ماشین جدید از او بخواهند.
اخیراً من با یک مدیرسیستم صحبت میکردم. او میگفت: ماه گذشته خیلی متعجب شده است که تیم توسعهدهندهها دیگر از او درخواست ماشین مجازی جدید نمیکنند. او گفت من نمیدانستهام چه شده است، با خود گفتم شاید به سراغ [سرویسهای ماشین مجازی] آمازون رفتهاند یا مشکلی برایشان رخ داده است، اما وقتی آنها را دیدم و علت را پرسیدم گفتند: «آیا به خاطر داری که هفته پیش یک ماشین مجازی قوی گرفتیم؟» گفتم: بله، و آنها گفتند که: «ما روی آن Docker را نصب کردیم و برای نرمافزارهای مختلف، تعدادی تصویر ساختیم و حالا تنها یک ماشین مجازی داریم و محفظهها را از روی آن تصاویر میسازیم و ما واقعاً خوشحالیم. این قطعاً در زمان شما هم صرفهجویی میکند زیرا دیگر مجبور نیستید که برخی تدارکات را ببینید و تصاویر و ماشینهای مجازی را برای ما نگهداری و راهاندازی کنید» در اینجا مدیر سیستم متوجه شد که دیگر مجبور نیست این کارها را انجام دهد، به جای آن میتواند انبوهی از کارها که واقعاً قصد داشته را انجام بدهد، کارهایی که در واقع ارزش بیشتری تولید میکنند. تیم توسعه هم دیگر مجبور نبودند که درخواست جدیدی برای دریافت منابع ثبت کنند و یا منتظر [آماده شدن] ماشینهای مجازی بشوند یا آنها را دوباره بسازند یا اینکه نگران این باشند که آیا ماشین مجازی که تحویل میگیرند، مشابه با سیستم محیط عملیاتی هست یا خیر و … . من فکر میکنم این ارزش خارقالعادهای برای تیم توسعه و هم تیم عملیات فراهم میکند.
بله، این مثال خوبی بود از ارزشآفرینی که برای توسعهدهندهها و همینطور مدیرسیستمها ایجاد میشود.
Docker خودش بر روی یک میزبان لینوکس اجرا میشود زیرا محفظهها از فایلسیستم لایهای و فضاهای نام (Namespace) و دیگر مواردی که شما اشاره کردید، بهره میبرند. بنابراین از لحاظ تئوری، سیستمهای مکینتاش و ویندوز نمیتوانند Docker را اجرا کنند. اما ابزاری با نام Boot2Docker وجود دارد که این امکان را فراهم میکند. آیا ممکن است مختصری در مورد آن صحبت کنید؟
قطعاً، در حال حاضر، Docker خیلی بر لینوکس استوار است و متکی بر کرنل لینوکس است اما قرار نیست همیشه این طور بماند. باگفتن این حرف رازی را فاش نمیکنم، [قبلاً] افراد در مورد آن صحبت کردهاند: نسبتاً ساده خواهد بود که با استفاده از چیزهایی از قبیل FreeBSD Jails بتوانیم Docker را بصورت یک شهروند بومی (Native Citizen) بر روی Apple یا FreeBSD اجرا کنیم. همین طور برای داشتن محفظههای بومی بر روی پلتفرم ویندوز هم تکنولوژیهای سبکی (Thin) مانند پروژه Hyper-V و چیزهای مشابهی مطرح هستند. اما در این اثناء در حالی که اینها هنوز اهداف آرمانی هستند، ما ابزاری با عنوان Boot2Docker را هم داریم. فکر میکنم Boot2Docker یک ماشین مجازی خیلی کوچک است. در واقع، یک کلاینت Docker بهمراه یک ماشین مجازی کوچک به نام DockerHost است که با یک برنامه نصب ساده برای ویندوز و مَک ارائه میشود که میتوانید آن را دانلود کرده و نصب و اجرا کنید. در این صورت، با استفاده از خط فرمان خود میتوانید با آن ماشین مجازی تعامل کنید. ما به نوعی وانمود میکنیم که DockerHost یک برنامهی محلی است. هنوز چالشهایی در مورد آن وجود دارد، هنوز مخفی نیست، شما مجبورید که برخی پیکربندیهای شبکه و … را انجام دهید، البته ما اغلب آنها را برایتان انجام میدهیم. Boot2Docker یک تجربه کاملاً بومی نیست اما چنانچه نرمافزارهایتان متکی بر ویندوز یا مک باشد، استفاده محلی از Docker را خیلی آسانتر میکند.
بله، قطعاً مواردی کاربرد جدیدی برای کاربرانی که در لینوکس توسعه نمیدهند، فراهم میکند.
ما اطلاعات کمی در ارتباط با مبانی Docker بیان کردیم. چنانچه شنوندگان میخواهند جزییات بیشتری بدانند، به آنها قویاً کتاب Docker ای که جیمز نوشته است را توصیه میکنم.
بیایید کمی به سراغ این برویم که چگونه از محفظههای Docker استفاده کنیم؟ شما کمی به آن وارد شدید، هر محفظه Docker یک دستور (Command) را اجرا میکند که به نوعی توصیه میکند که هر محفظه Docker تنها یک سرویس را اجرا کند. آیا این دلیل خاصی دارد؟ شما به معماری سرویسگرا و ریزسرویسها اشاره کردید. منظور سئوال من این است که آیا دلیل فنی داشته یا نوعی دلیل فلسفی بوده که شما فکر میکنید توسعهدهندهها باید به روش معماری سرویسگرا و ریزسرویسها کار کنند؟
در واقع، دلیل فنی نیست و بیشتر به دلیل فلسفی میماند. چیزی جلوی شما را نگرفته است که چندین پروسس را بر روی یک محفظه Docker اجرا کنید، شما میتوانید از ابزارهای مدیریت سرویس مانند systemd یا Supervisor یا چیزهای مشابه آن استفاده کنید تا بتوانید مثلاً کل Stack LAMP را اجرا کنید یعنی Apache، MySQL و PHP همگی را داخل یک محفظه Docker اجرا کنید اما در این صورت نرمافزارها پیچیده و پیچیدهتر میشوند و ارتباط بین آنها -مواردی از قبیل پورتهای باز شده، انواع مختلف کنترل دسترسیها، پیکربندیها، یکپارچهسازیها و …- پیچیدهتر میشود.
مشکلات زیرساختهای بزرگ که خلال چند سال گذشته، با آن روبرو بودهایم به علت این بوده است که افراد نمیدانستند نرمافزارهایشان چطور با هم تعامل دارند. خصوصاً در سیستمها معظم (Enterprise)، افرادی که نرمافزار اصلی را نوشتهاند دیگر در شرکت کار نمیکنند و [به جای آن] مقداری دانش به ارث برده شده و حجمی از دادههای مستندشده وجود دارد و بخش عمده اشکالزدایی مشکل تنها مربوط به شناسایی این است که هماکنون نرمافزارها چطور کار میکند و چطور با هم صحبت میکنند.
فکر میکنم در دنیای معماری سرویسگرا و ریزسرویسها، میتوانید بگویید: من در نرمافزارم 10 محفظه دارم، من راهی برای بازرسی آنها و مشاهده چگونگی متصل شدن آنها به هم دارم – ما قبلاً در مورد لینک بین محفظهها و باز کردن پورتها صحبت کردیم- من میتوانم همه اینها را عملگرایانه واکاوی کنم و ببینم که بله، من 10 محفظه دارم که فلان پورتهایشان باز شده است، فلان محفظه و فلان محفظه و فلان محفظه به فلان شکل به هم لینک شدهاند و …، به این طریق، میتوانم متوجه اساس معماری نرمافزارم بشوم و بفهمم فلان محفظه است که باعث مشکل شده است فکر میکنم این نوع تجربههای خطازدایی خیلی سادهتر است. من دارم از قول کسی میگویم که در چند سال گذشته بیشتر بر روی برطرف کردن مشکلات عملیاتی (Operational) تمرکز داشته است. همچنین فکر میکنم دیدگاه معماری سرویسگرا، از لحاظ تولید نرمافزارها و تقلید (Mocking) و تست کردن آنها و همینطور از لحاظ قابلیت دیگر افراد برای تعامل برقرار کردن با آنها، کار را خیلی سادهتر میکند. مثالهای تامهای برای آن وجود دارد مثلاً Amazon یک نمونه کلاسیک آن است. گروه توسعهدهندههای Amazon، API ها را به این روش منتشر میکنند که همه چیزهای داخل آن برای توسعهدهندههای گروههای دیگر به نوعی، جعبهسیاه است و تنها بیان مشخصات API (API Spec.) منتشر میشود و گروههای دیگر سرویسهایشان را برآن اساس مینویسند. این شاید کمی افراطی باشد اما به نظر من، خیلی از نرمافزارها و سرویسها وجود دارند که با این جهتدهی، ساختن آنها و مدیریت کردن و تست آنها، خیلی سادهتر است، یعنی چنانچه [تنها] بیان مشخصاتی از API، سرویس یا فرمت دادهها و یا فرمت Protobuf آنها منتشر شود و دیگران برآن اساس، مصرفش کنند. این دلیل بوده است که Docker را به این نوع نگاه هدایت کرده است.
اگر من نرمافزاری داشته باشم و آن را به تعدادی سرویس مجزا تفکیک کنم و هر سرویس را در محفظه خودش قرار دهم، چگونه میتوانم آنها را راه بیاندازم و اتصالات بین آنها را برقرار کنم فرضاً اگر برای اتصال سرور برنامهام به پایگاه داده از یک لینک استفاده کرده باشم، چطور همه آنها را راه بیاندازم و وابستگیهای بین آنها را رسیدگی کنم مثلاً مواردی از این قبیل که پایگاه داده باید قبل از برنامه اجرا شود و …
این ناحیهای [از نیازمندیها] است که خیلی سریع در حال توسعه است. در حال حاضر Docker کمی بیش از یک سال عمر دارد. فکر میکنم یک سال و نیم باشد. (زمان ضبط این مصاحبه، تابستان سال 2014 بوده است -مترجم) بنابراین مثل نطفهای میماند که بر روی انواع مختلفی از تکنولوژیها ایستاده است. اعضای اولیهی آن روی بخشهای پردازشی [متمرکز] بودهاند و اکنون مرحله بعدی که ما به آن فکر میکنیم ماجرای همنواسازی (Orchestration) است. شما مثال کلاسیکش را گفتید که یک وبسرور را میخواهید راه بیاندازید اما به این نیاز است که اول پایگاه داده راه انداخته شود. این مثال سادهاش است، میتوان مثالهای پیچیدهتری داشت که مثلاً چندین پایگاه داده در نواحی مختلف جغرافیایی قرار گرفته باشد یا چندین لایه برنامه داشته باشیم و … . ما در اکوسیستم Docker، متوجه نیاز به ابزار Config شدیم. Config یک ابزار سازماندهی است که به شما اجازه میدهد که مجموعهای از محفظهها تعریف کنید. در آن گفته میشود که یک سرویس از فلان محفظه و فلان محفظه ساخته شده است و آنها را به این ترتیب اجرا کن و به هم لینکشان کن. بنابراین، این [ابزار] برخی از این گونه مشکلات را حل خواهد کرد. در نتیجه آن حجم زیادی از ابزارها، به اکوسیستم اضافه خواهد شد که شامل یکپارچهسازی با چیزهایی از قبیل ZooKeeper و ابزارهای مرتبط با کشف سرویس هم خواهد بود. بنابراین یکی از گامهای جذاب بعدی تولید همین ابزارهای همنواسازی و مدیریتهای شخصیسازی شده خواهد بود.
و آیا قرار است امکان اجرای محفظهها بر روی چندین میزبان هم اضافه شود؟ تا الان ما داشتیم در مورد اجرای Docker بر روی یک میزبان کوچک و منفرد صحبت میکردیم. درسته؟
ما یک پروتوتایپ ابزار با نام libswarm منتشر کردهایم. این ابزار در واقع برای این طراحی شده است تا پروتوتایپی در مورد نحوه صحبت کردن میزبانهای Docker با همدیگر باشد. در حال حاضر محفظههایی که بر روی یک میزبان Docker قرار گرفتهاند باید از شبکه برای صحبت با یکدیگر استفاده کنند اما واقعاً باید یک کانال ارتباطی پشتی برای این منظور میداشتند. ما باید به امر تعاملات بین Docker ها فائق بیاییم. اینکه یک میزبان Docker بتواند بگوید که: «من یک میزبان Docker هستم و یک سرویس وب Apache دارم» و یک میزبان دیگر بگوید: «من هم یک پایگاه داده دارم که باید Apache آن را بیابد. آیا میتوانی یکی از محفظههای خود را به یکی از محفظههای من لینک کنی؟»
به این ترتیب با این امکانات، میتوانید ماجراهای بسیار هیجانانگیزی از قبیل مقیاسپذیری، افزونگی و … را مدیریت کنید. میتوانید برنامههای واقعاً پیچیدهای را راه بیاندازید که تا کنون برای سازمانها خیلی پرچالش بوده است.
Docker چطور با جنبش زیرساختهای تغییرناپذیر (Immutable Infrastructure) در DevOps تطبیق پیدا میکند؟ آیا Docker جایگزین یا رقیبی برای ابزارهایی از قبیل Chef و Puppet است؟
فکر میکنم بیشتر مکمل هم هستند. زیرساختهای تغییرناپذیر در واقع نرمافزارهای بدون حالت هستند. شما یک واحد محاسباتی که در اینجا همان محفظه است را میسازید که میتواند شامل سورسکد و همه چیزهای دیگر باشد اما در آن دادههایی برای بروزرسانی یا پایگاه داده نیست بلکه یک سیستم بسته است و در پردازشهای با کارایی بالا در حوزههای دارویی و علمی خیلی رایج است. همین طور در کارگاههای آموزشی عملیات وب خیلی رایج شده است زیرا همانطور که گفتیم علت خیلی از مشکلات این است که آشفتگی پیش میآید و تغییرات تدریجی رخ میدهد بنابراین میزبان شما تفاوت پیدا میکند، در این مثال، اگر بخواهید میزبان را دوباره بسازید میتوانید که آن را پاک کرده و یک نمونه جدید بسازید و تضمین شده است که به آخرین حالت خوب قبلی برگشت داده میشوید.
Puppet و Chef و همینطور Ansible و Salt همگی برای مدیریت این آشفتگیها و تغییرات تدریجی در پیکربندی بوجود آمدهاند. [اگر از محفظهها استفاده کنید] احتمالاً نیاز کمتری به استفاده از آنها خواهید داشت زیرا محفظهها خیلی خیلی کوتاهعمرتر هستند و تغییرناپذیر (Immutable) هستند. خیلی ارزانتر خواهد بود که به جای استفاده از Puppet و Chef ، یک محفظه را به حالت قبلی خود بازسازی کنید. ممکن است از آنها فقط برای این منظور استفاده کنید که محفظهها را از بین برده و نمونههای جدید از آنها بسازید. در این صورت Puppet و Chef نقش مکمل را خواهند داشت به این معنا که میزبان Docker به جای مدیریت شدن نیاز به تدارک دیده شدن دارد. به این ترتیب که تصاویر بعدی Docker باید تولید شود. شما داخل ماژول Puppet یا دستورالعمل Chef احتمالاً اطلاعات مفیدی درباره چگونگی ساختن برنامه خود را دارید. وقتی بخواهید آنها را برای Docker بکار ببرید، دیگر نیازی نیست که بخش نگهداری مبتنی بر امور بلندمدت را داشته باشید و تنها اگر بخواهید، آنها [محفظهها] را نابود و دوبارهسازی میکنید.
بله، قطعاً میتوانم یک جنبه مکمل بودن را در آنها ببینم.
من شنیدهام که محفظههای Docker به محفظههای موجود در صنعت حمل و نقل در کشتیها، قطارها و کامیونها، تشبیه میشود. آیا ممکن است کمی آن را توضیح دهید.
این تشبیه Docker به بنادر و محفظهها و اصطلاحات این صنعت چیزی است که ما آن را هنگام توسعهی زبان خیلی بسط نمیدادیم. پیش از محفظههای چند منظوره (محفظههای بزرگ فولادی که با آن آشنا هستید و در کشتیهای باربری قرار میگیرند) کاری که انجام میشد این بود که یک صندوقدار یا تحویلدار در کشتی وجود داشت. کار آنها این بود که کالاها را تحویل گرفته و طوری در کشتی قرار دهند که از ظرفیت تجاوز نکند، باروت کنار کبریت نباشد و تمام مراقبتهای دیگری که مثلاً برای نگهداری ادویههای گرانبها لازم است را انجام میدادند. اینها فرآیند بارگذاری و تخلیه را کاملاً دشوار میکرد. اغلب روزها طول میکشید تا کشتی را بادقت بار بزنند. این به آن خاطر آن بود که اگر در سفر مشکلی پیش میآمد مثلاً اگر آب وارد چیزی میشد احتمال زیادی وجود داشت که بخشی از محموله خود را از دست بدهید. این، سربار قابل توجهی به فرآیند حمل و نقل میافزود تا اینکه محفظهها مطرح شدند و فردی آمد و گفت: چطور است که جعبههایی بسازیم که همگی یکسان باشند؛ همگی قلابها سیستم برچسبگذاری یکسانی داشته باشند تا یک سیستم یکپارچهی شناسایی داشته باشیم. در آنصورت دیگر اهمیت نخواهد داشت که چه چیزی را داخل آنها بار بزنیم زیرا از هم تفکیک شدهاند و کاملاً قابل حمل خواهند بود. میتوانید آنها را از کشتی تخلیه کنید و در کامیون بگذارید و نیازی نیست به عنوان بخشی از این فرآیند حتی محفظهها را باز کنید.
وقتی ما Docker را میساختیم فکر میکردیم که این تشبیه، واقعاً مناسب است. ما واقعاً اهمیت نمیدادیم که چه چیزی را در داخل محفظهها قرار میدهید. میتواند 10 عدد وبسرور باشد یا یک پایگاه داده بزرگ باشد یا یک سرویس منفرد باشد، هرچه که بخواهید میتواند باشد اما آنچه ما برایتان فراهم میکنیم روشی برای انتقال این محفظه از طریق تصویر آن به جاهای دیگر است و روشی برای تیم عملیات فراهم میکنیم که قلابها و برچسبهای یکسانی داشته باشد تا به این ترتیب تیم توسعه واقعاً به ظرفیت داخل محفظهها توجه کنند و تیم عملیات به مدیریت آن فکر کنند یعنی مانند صنعت حملونقل، به نوعی به جابجایی آن، برداشتن آن از کشتی با جرثقیل و قرار دادن آن در کامیون، فکر کنند. به همین علت بود که این تشبیه برای ما تقویت میشد البته تشبیه کاملی نیست، ممکن است بحث شود که این یک مثال خوب و سادهشده از تاریخچه صنعت ترابری مدرن است اما نه اینگونه نیست. این بیشتر از جنبه بازاریابی آن است تا اینکه یک ماجرای فلسفی عمیق باشد.
اما باز هم نتیجه نهایی آن خیلی مشابه است. شما در مورد تسهیل چشمگیری که در بارگذاری و تخلیه کالاها در کشتیها، کامیونها یا قطارها ایجاد میشود، صحبت کردید و [از طرفی هم] برای ما مثالهایی از بهبود کارایی که در این محفظههای ماشینهای مجازی و تسریعی که در امور توسعه و عملیات ایجاد میشود صحبت کردید.
چیزی که به آن اشاره نکردم این بود که بعد از اینکه محفظههای چند منطوره معرفی شد، زمان حمل و نقل 70 درصد کاهش یافت. در مورد هزینهاش هم دقیقاً نمیدانم، من در دهه 40 زندگیام هستم و این مربوط به قبل از تولد من است اما پدر و مادرم به خاطر دارند که مثلاً ارسال یک کالای مصرفی از استرالیا به انگلیس یک کار کاملاً پرهزینه و غیرمتعارف بوده است و ممکن بود 6 تا 8 هفته منتظر میشدید تا یک بسته از لندن به سیدنی برسد. فرآیند محفظههای چند منظوره به شدت تجارت و حمل و نقل بینالمللی را تسریع کرد و در واقع، روش تجارت افراد را تغییر داد. به همین خاطر است که ما از این تشبیه استفاده میکنیم. ما فکر میکنیم این ظرفیت وجود دارد که این [استفاده از محفظهها] باعث تغییرات اساسی در روش تولید، مدیریت و انجام امور عملیات نرمافزارها شود و روش آتی در انجام پردازشها و کارها باشد.
بنابراین خیلی دشوار است که همان مرتبه از بهبود حاصل شود…
واضح است که هنوز چالشهایی وجود دارد اما فکر میکنم لازم است افراد به خاطر بیاورند که چه تاریخچه مختصری در این مورد داریم. خود ماشینهای مجازی تکنولوژی نسبتاً جدیدی به حساب میآید، اولین چیزی که واقعاً تجاری شد، VMWare بود که حدود 10-11 سال عمر دارد و به عنوان یک تکنولوژی، به نسبت نوپا است.
به وضوح ماشینهای مجازی، به شدت نحوه کار با زیرساختها را دگرگون کرده است. در واقع، آنها سرویسهای ابری را ممکن ساختند؛ بدون ماشینهای مجازی سرویسهای ابری و برخی موارد دیگر، وجود نداشت. اینها در مدت زمان کوتاهی رخ داد. اکنون که به مفهوم سرویسهای ابری نگاه میکنیم، تبدیل به یک چیز عادی شده است. مثلاً اینکه که سروری داشته باشید که 100 ماشین مجازی را اجرا میکند، 20 سال پیش جزء بیشتر به معجزه شبیه بود. و من کارم را در دنیای MainFrameها شروع کردم که در آن چیزهایی مثل پارتیشنبندی منطقی (Logical Partitioning) مطرح بود که مثل یک مجسمهی یادبود یک میلیون دلاری بود. بنابراین فکر میکنم طی 10-12 سال گذشته تغییرات جذابی در مورد مدیریت زیرساختها را دیدهایم، امیدوارم Docker، ادامه راه تغییرات بعدی خلال 4-5 سال آینده باشد.
قطعاً، کاملاً منطقی به نظر میرسد. آیا به نظر شما Docker، یک جایگزین برای روشهای سنتی مجازیسازی سختافزار است؟
فکر میکنم در محیطهای پلتفرم به عنوان سرویس (Platform as a Service) و زیرساخت به عنوان سرویس (Infrastructure as a Service) مانند OpenStack و CloudFoundry و Amazon ماشینهای مجازی در واقع منابع ایدهآلی برای پردازش نیستند. آنها کاملاً سنگین هستند و سربار چشمگیری به زیرساختهای شرکت اضافه میکنند. فکر میکنم برای انواع مشخصی از کارهایی که در فضای سرویسهای ابری به آن علاقه نشان داده میشود، [بکارگیری] محفظهها خیلی منطقیتر است. شما به زیرساختهای تغییرناپذیر (Immutable Infrastructure) و پردازشهای با کارایی بالا اشاره کردید، اینها طبیعتاً با Docker سازگاری دارند. همینطور برای هرکسی که معماری سرویسگرا یا ریزسرویس داشته باشد و یا گذرگاه سرویس و چیزهای مشابه داشته باشد، Docker ایدهآل است. من قویاً توصیه میکنم که نگاهی به آن بیاندازند. Docker به طور طبیعی کمک میکند که با یک روش کاملاً سالم به معماری خود بیاندیشید. البته واضح است که برخی سرورهای فیزیکی یا کارهای خاص یا میراثی (Legacy) هم وجود دارند که نمیتوانید به سمت این نوع معماری بروید. من اخیراً به شرکتی رفتم که نرمافزارهای گستردهای بر روی کوبول داشتند و جایگزین کردن آن با محفظههای Docker واقعبینانه نبود. همینطور الان Docker خیلی متمرکز بر لینوکس است. اما خصوصاً در دنیای توسعه و تست که در مورد یکپارچهسازی مستمر (Continuous Integration) میاندیشیم و نگرانیهای اصلیمان مساعی و همکاری در کارها، مدت زمان رسیدن محصول به بازار (Time to Market) و انتقال کد از محیط توسعه به محیط عملیات است، Docker یک زمینه جذاب است.
ابزارهای زیادی داخل و حول Docker به وجود آمده است. ما به تعدادی از آنها اشاره کردیم. شما به Fig اشاره کردید. موارد خیلی زیادی هست مثلاً CoreOs ، Messos ، Panamax و … . فکر میکنید چرا اکنون Docker این حد پرطرفدار شده است و این همه فعالیت را به خود جذب کرده است؟
شما قبلاً کمی درباره Solar Zones و FreeBSD Jails صحبت کردید. قبل از Docker در دنیای لینوکس، محفظههای LXC اجرا میشد که محفظههای لینوکس هم خوانده میشدند و ما برخی از ایدههای خود را از آن تکنولوژی برگرفتیم. فکر میکنم مشکل بزرگ همه این تکنولوژیها این بود که استفاده کردن آنها به واقع ساده نبود.
Solar Zone ، FreeBSD Jails ، LXC ، chroot اینها، همگی به یک مدیر سیستم زیرک یا یک مهندس زیرکتر برای توسعه نیاز داشتند تا بتوان با آن کار کرد. بنابراین اولین چیزی که ما به دنبالش بودیم این بود که Docker رویهای داشته باشد که توسعهدهندههایی که هیچ چیزی در مورد زیرساختها نمیدانند بتوانند از آن استفاده کنند. هر زمانی که میخواستیم چیز [جدیدی] بسازیم، باز به این توجه میکردیم که منجر به افزایش پیچیدگی نشود که بخواهد مانع استفاده از آن ابزار توسط یک مهندس جلوکار (Front-end Engineer) بشود که هیچ اطلاعی در مورد ماشینهای مجازی، مجازیسازی و پشتهای که برنامه بر روی آن اجرا شده، ندارد. تمرکز ما بر این بوده است و عامل حجم چشمگیری از استنتاجها همین بوده است. این واقعیت [مهمی است] که توسعهدهندهها میتوانند در مدت زمان خیلی کوتاهی، Docker را اجرا و استفاده کنند و نیازی نیست که هیچ چیزی در مورد کرنل لینوکس و نحوه کارکرد فضاهای نام (Namespace) و گروههای کنترلی (CGroup) بدانند، نیازی نیست هیچ چیزی در مورد زیرساختها بدانند و تنها به دانستن تعدادی دستورات خیلی ابتدایی و امور شبکهای خیلی ابتدایی نیاز دارند مثلاً اینکه فلان پورت به فلان پورت دیگر نگاشت یافته است. اینها، چیزهای واقعاً سادهای هستند.
من قبلاً این مثال را زدم که دیگر نیاز نیست با مدیرسیستم صحبت کنید تا یک منبعی دریافت کنید. این برای توسعهدهندهها، چیز مهمی است. دیگر مجبور نخواهند بود که یک تیکت درخواست ثبت کنند که من یک کپی از پایگاه داده محیط عملیاتی را میخواهم که بر روی یک ماشین مجازی در محیط تست ایجاد شود و کلی منتظرش شوید، نه به خاطر اینکه مدیر سیستم وقت را تلف میکند بلکه به خاطر اینکه آنها علاوه براینکه سعی میکنند سرویسهای فعال باشمد به هزارها تیکت مانند آن جواب میدهند. به این طریق، کمک میشود این نوع تعاملات ترسناک کاهش یابد. به همین خاطر است که توسعهدهندهها عاشق آن هستند. افراد تیم عملیات هم، آن را دوست دارند زیرا به طبیعت مقیاسپذیر جذاب آن مینگرند، برخی از آنها صورتحسابهای خیلی سنگینی، به شرکتهایی مانند VMWare پرداخت میکردهاند و ماشینهای مجازی و لایسنسهای زیادی خریداری کرده بودند. به این ترتیب امیدوارند مقداری از این هزینهها کاسته شود و مدیریت کارها راحتتر شود یا اینکه از برخی بحثهای بین آنها و توسعهدهندهها کاسته شود که توسعه دهنده بگوید بر روی ماشین من کار میکند و فرد عملیاتی بگوید اما در محیط عملیاتی برای مشتریها کار نمیکند. من 25 سال به عنوان مهندس در تیم عملیات مشغول بودهام. میتوانم مثالهای بیشماری از بحثهایی بزنم که در محوطه پردیس و اغلب در ساعت 4 صبح داشتهام که برخی توسعهدهندهها [به نشان ناامیدی] دستشان را بالا میبرند و میگویند که وقتی من آن را build کردم برایم کار میکرد، مشکل تو چیه؟ تو احمقی! و متأسفانه این گونه تعاملات متداول است و خوشایند نیست. اگر بتوانید ذرهای از آن بکاهید ارزش مالی خیلی زیادی دارد؛ از لحاظ زمان فعال بودن [سرویس] و روحیه و همکاری [افراد] و سایر چیزها. به همین خاطر به نظر من خیلی هیجانانگیز است.
چه چیزهایی برای آینده Docker در نظر گرفته شده است؟ شما به نوعی به آنچه ممکن است اتفاق بیفتد اشاره کردید.
بله، ما داریم خیلی سخت روی محصول DockerHub کار میکنیم که امکانات خیلی بیشتری در آن قرار دهیم تا اعتبارسنجی بهتری در ارتباط با مفاهیمی از قبیل تیم و سازمان و مخزنهای خصوصی و عمومی داشته باشد. اینها این امکان را خواهد داد که افراد بتوانند به همان طریقی که مثلاً از GitHub استفاده میکنند با آن کار کنند.
[مورد دیگر] این است که به GitHub قلاب بخورد و بتوانید برآن اساس کارهایی را انجام دهید مثلاً اگر سورسکدهای خود را در GitHub داشتید و تغییراتی در سورسکدهای خود در GitHub دادید تصاویر Docker بصورت خودکار بروزرسانی شود. این میتواند خیلی جالب باشد. ما بدنبال گسترش آن هستیم. ما یک محصول متن باز داریم که بخشی از این عملکرد را فراهم میکند. ما میخواهیم کل DockerHub را به صورت در-محل (On-premises) ارائه کنیم. احتمالاً ابتدای سال آینده این کار را خواهیم کرد. همه کسانی که در مورد ارسال اطلاعات خصوصی خود به خارج از فایروال خود ناراحت بودند میتوانند دقیقاً مانند GitHub Enterprise آن را بصورت داخلی مدیریت کنند.
و بر روی خود محصول Docker، در جهت افزایش زنجیره ارزش آن حرکت میکنیم. در حال حاضر، ما در مدیریت گروههای کوچک محفظهها بر روی یک میزبان ِDocker خوب هستیم. ما میخواهیم برنامههای پیچیده که بر روی چندین میزبان Docker در مناطق مختلف قرار گرفتهاند را بصورت خودکار مدیریت کنیم. تکنولوژی که حول آن کار میکنیم این است که نحوی از خودکارسازی داشته باشیم که استفاده از آن برای افراد واقعاً ساده باشد، توسعهدهندهها باید بتوانند بدون درگیر شدن با تعداد زیادی از افراد دیگر، یک پشته ساده بسازند و افراد تیم عملیات باید به همه امکانات دسترسی داشته باشند، و به این صورت درخواست توسعهدهندگان را پاسخ میدهیم.
چیزی که شما الان اشاره کردید اما من صراحتاً به آن اشاره نکرده بودم این است که Docker یک ابزار متنباز است و هرکسی آزاد است که از آن استفاده کند. Docker همینطور نام شرکت پشت سر پروژه Docker هم هست. مدل تجاری این شرکت چگونه است؟ آیا نواحی مشخصی از این اکوسیستم و محوطه [ابزارهای مرتبط با Docker] هست که شرکت برای خود مدنظر قرار داده است؟
در واقع، شرکت Docker به دو علت وجود دارد، یکی این است که ما بسیاری از سرپرستیهای حول پروژه Docker را انجام میدهیم. ما اخیراً با خود پروژههای متنباز، مشارکتهای گستردهای داشتهایم.
مدل تجاری ما برپایه چند چیز است. یکی در پروژه DockerHub است، [در آنجا] باید بابت مخزنهای اختصاصی که به آنها اشاره کردم پرداخت کنید، دقیقاً مشابه با خرید مخزنهای اختصاصی در Git Hub است. همینطور ما سرویسهایی بر روی آن داریم (فکر میکنم 4 سرویس باشد) که فکر میکنیم برای خیلی از افراد جذاب باشد [و این سرویسهای اضافی پولی است].
به علاوه ما خدمات آموزشی مرتبط با ابزار متنباز Docker ارائه میکنیم، کمک میکنیم که کار با Docker را شروع کنید، ما کلاسهای آموزشی داریم، کلاسهای عمومی دوروزه و ….، خدماتی داریم که کمکتان میکنیم برخی مفاهیم قدیمی را با Docker اجرا کنید و آن را راه بیاندازید. و همینطور، خدمات پشتیبانی ارائه میدهیم، اگر مشکلی داشته باشید میتوانید از ما بپرسید.
در آینده، قرار است محصولات بیشتری در این زنجیره ارزش توسعه دهیم. ما فکر میکنیم افراد حاضرند بابت این محصولات، پرداخت داشته باشند. یکی از چیزهایی که البته فقط مربوط به دنیای محفظهها نیست، بلکه حوزهاش وسیعتر است، یک ابزار واقعاً قدرتمند همنواسازی (Orchestration) و یک ابزار واقعاً قدرتمند مدیریت سرویس (Service Management) است. فکر میکنم این ابزارها در دسترس عموم نیست یا خیلی خیلی گران هستند. BMC یا HPOpenView یا حتی محصولات VMWare که اخیراً به جریان افتاده و … همگی نیاز به استعدادهای مهندسی قوی دارند. مثلاً ZooKeeper واقعاً ابزار فوقالعادهای است اما نیاز به تجربههای خیلی بالغ مهندسی دارد و مهندسی خیلی قوی نیاز است تا بتوانید آن را با محیط خود تطبیق دهید، اینها ابزارهای آماده مصرف نیستند. بنابراین ما فکر میکنیم اگر بتوانیم ابزارهای همنوایی و مدیریت واقعاً قوی داشته باشیم که با تمرکز بر روی Docker باشد اما با این امید که بتوانیم با ابزارهای دیگر هم یکپارچه شویم، افراد حاضر خواهند شد که برایش پول بدهند.
آیا فکر میکنید مطلبی هست که پوشش نداشته باشیم و شنوندگان بخواهند در موردش بدانند؟
فکر میکنم تقریباً همه چیز را پوشش دادیم. فکر میکنم به قدری تشریح کردیم که افراد را تشویق کرده باشد که Docker را یک امتحانی بکنند، به مقدار کافی پوشش دادیم.
برای امتحان کردن آن، افراد کجا میتوانند اطلاعات بیشتری در مورد آن بدست بیاورند و شما را دنبال کنند؟
آدرس وبسایت، www.docker.com است. در آن جا، خودآموزهای خیلی سادهای وجود دارد. فکر میکنم در بالای صفحه لینکی با عنوان Try it! وجود دارد که شما را به یک خودآموز 5 دقیقهای هدایت میکند که یک آشنایی خیلی ساده ایجاد میکند و بعد برای شما تعدادی لینک برای دسترسی به مستندات، نحوه نصب و نحوه شروع به کار قراهم میکند. من همینطور کتابی با عنوان کتاب Docker نوشتهام که از آدرس www.dockerbook.com در دسترس است که واقعاً یک آشنایی ساده فراهم میکند و هیچ پیشفرضی در مورد دانش شما ندارد و کمکتان میکند که از صفر تا کارهای به اصطلاح کاملاً پیچیده را انجام دهید. من از بیاطلاعی کامل از Docker شروع کرده و از نصب Docker، ساختن تصاویر Docker، انجام امور خیلی ابتدایی Docker تا کارهای پیچیده کشف سرویس با معرفی ابزارهایی مانند Fig و Consul و … و همینطور گسترش دادن Docker توسط خودتان و یکپارچه شدن با Docker از طریق API یکپارچهسازی را بحث کردهام. این کتاب از ماه جولای [سال 2014] در دسترس قرار گرفته است. این کتاب خیلی ارزان است (9.99 دلار). و در ارتباط با خودم، میتوانید من را در توییتر به آدرس @kartar بیابید، وب سایتی هم به آدرس kartar.net دارم که تعدادی مطلبهای بلاگ و برخی مقالات مورد علاقه من آنجا وجود دارد.
جیمز، از اینکه به مصاحبه آمدید، تشکر میکنم.
خیلی ممنون که دعوتم کردید، خیلی خوش گذشت.