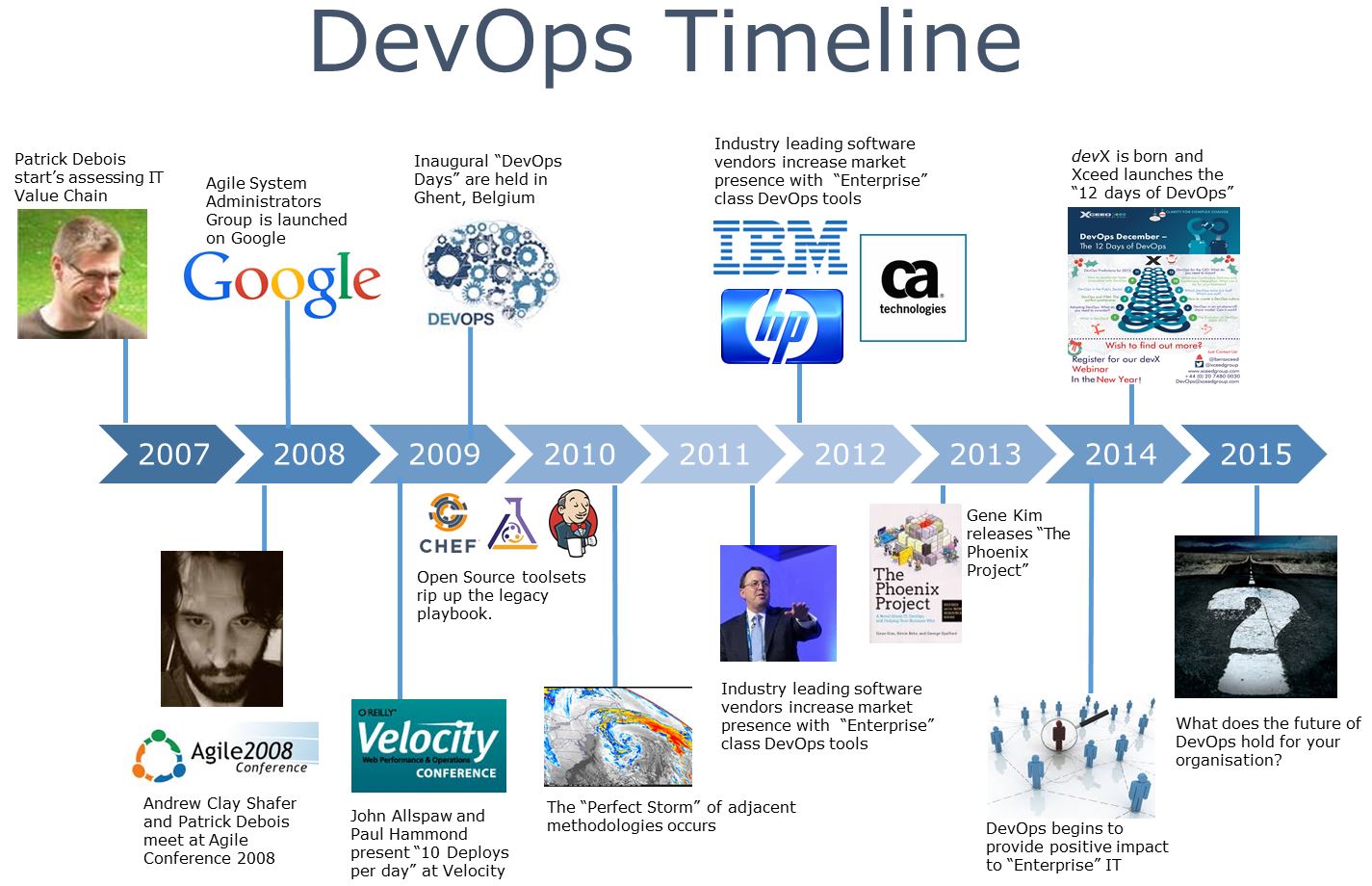
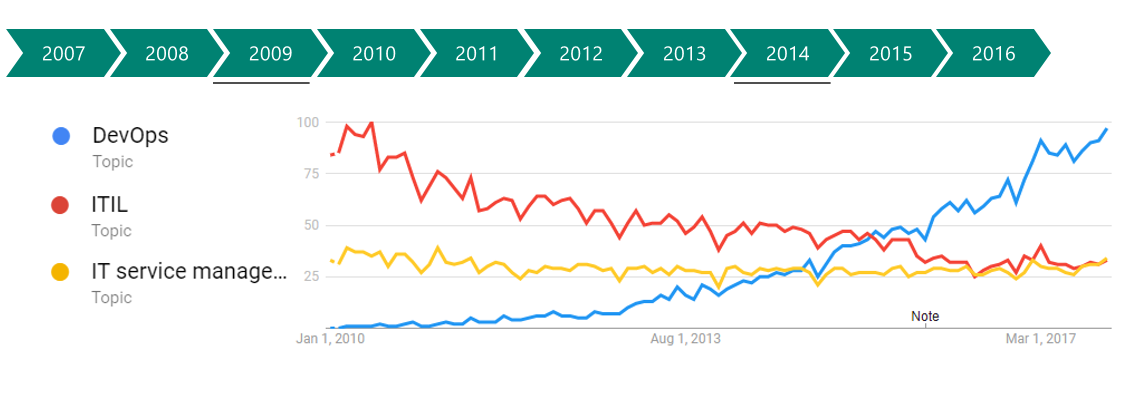
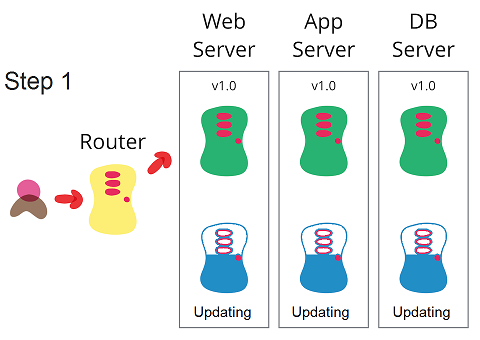
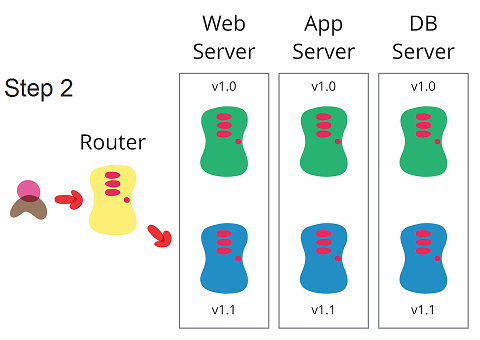
شاخص های کلیدی عملکردی دواپس یا DevOps KPI که قبلا به چهار دسته سرعت، کیفیت، بهره وری و امنیت تقسیم کردیم را چطور ارزیابی میکنید؟ در این مطلب یازده شاخص کلیدی عملکرد، اصول و پایه های لازم برای ارزیابی موفقیت DevOps را معرفی و بررسی کرده ایم.
 شاخص های سرعت دواپس | DevOps Velocity KPI
شاخص های سرعت دواپس | DevOps Velocity KPI
در مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” به دلیل اندازه گیری و ارزیابی سرعت اشاره کردیم. اما با چه سنجه و متریک هایی می توان سرعت را اندازه گیری کرد؟ در اینجا قصد داریم چهار شاخص عملکرد کلیدی سرعت دواپس را معرفی و شرح دهیم.
1. فرکانس استقرار | Frequency of deployment
مفهوم: مشخص میکند که هر چند وقت یکبار نسخه جدیدی از یک محصول یا سرویس ارائه میشود. و به صورت تعداد استقرارها در ماه، هفته، روز یا ساعت ارزیابی می شود.
دلیل اهمیت: استقرارهای مکرر و پی در پی نشان دهنده بهبود مستمر اپلیکیشن ها است که با افزودن ویژگی های تازه به آن ها، باعث ایجاد قابلیت رقابت در آن ها می شود. همچنین بروزرسانی های مکرر نشان می دهد که بخش IT در برابر تقاضای بیزینس برای ویژگی های جدید پاسخگو است. یک بیزینس در صورتیکه مشاهده کند که به جای شش ماه یکبار، هر ماه شاهد اضافه شدن ویژگی ها و امکانات جدید توسط بخش IT است، قدردان بخش IT خواهد بود. (اما فراموش نکنیم که استقرار بیش از حد مکرر ممکن است نشان دهنده این باشد که به دلیل عجله زیاد، مدام نرم افزارهای معیوب تولید می کنید.)
همچنین این معیار به سایر حوزه های استقرار نرم افزار که عملکرد درستی دارند هم اشاره می کند:
- طراحی بهتر معماری در فازهای ابتداییتر DevOps: ماژولار کردن، امکان استقرار مکرر و پی در پی را فراهم می کند.
- پوشش بهتر تست: اگر تولیدات بیشتری را مورد استفاده قرار دهید، عوامل مربوطه حس می کنند که می توانند محصولات را با فرکانس بالاتری مستقر کنند.
قبلا دو مطلب در رابطه با استقرار نرم افزار منتشر کردیم که خواندن آن خالی از لطف نیست :
2. سرعت استقرار | Speed of deployment
مفهوم: یک استقرار واحد، برای یک محصول یا سرویس خاص چقدر زمان می برد. این معیار به صورت تعداد ساعات سپری شده از تایید استقرار تا اجرای آن در محیط بعدی بیان می شود.
دلیل اهمیت: در روش های سنتی، سیستم های شرکتی اتصال تنگاتنگی دارند(tightly coupled هستند)؛ هر زمان چیزی مستقر می شود، ممکن است در نهایت نیاز به استقرار مجدد کل اپلیکیشن باشد. یک دهه پیش، این امر قابل قبول بود – می توانستید از کار افتادگی پنج ساعتهی ویندوز را برای نیمه شب زمانبندی کنید، بدون این که این از کار افتادگی تاثیر منفی برای بیزینس داشته باشد. اما مشاغل امروزه جهانی هستند – مثلاً وقتی در امریکا نیمه شب است، در آسیا روز است – و اکثر شرکت ها در همه اوقات مشتریانی دارند که بیدار هستند. بنابراین سریع بودن استقرار امری حیاتی است.
امروزه، سیستم ها باید کمتر به هم وابستگی داشته باشند. به این ترتیب، می توان سرویس های خاص را بدون تاثیر بر کل سیستم تغییر داد. با استفاده از میکروسرویس ها و APIهایی که به وضوح تعریف شده و امکان کپسوله کردن و دسترسی آسان را فراهم کنند، می توانید سرعت استقرار را به میزان زیادی افزایش دهید.
بعلاوه افزایش سرعت استقرار نشان دهنده افزایش ثبات (سازگاری) در خط لولهی دواپس (DevOps Pipeline)، با جایگزینی کارهای دستی پرخطا در چرخه عمر محصول، توسط اتوماسیون است.
3. سرعت تایید بیلد ها | Speed of build verification (QA)
مفهوم: کل زمان حرکت یک محصول در چرخه QA
دلیل اهمیت: اکثر اوقات QA تبدیل به یک تنگنا می شود. ارزیابی زمان سپری شده برای یک محصول تولیدی در QA اطلاعات کلیدی درباره اینکه با چه سرعت و فرکانسی می توانید یک محصول یا سرویس ارائه دهید، در اختیارتان قرار می دهد. وقتی مقدار این سنجه بالا باشد، متوجه می شوید که می توانید فرکانس را بدون اینکه QA تبدیل به تنگنا شود، افزایش دهید. اگر این مقدار پایین باشد، نشان می دهد که نیاز به پیاده سازی تکنیک هایی مثل اتوماسیون تست در خط لولهی انتشار محصول دارید (release pipeline).
4. فرکانس تایید بیلد ها | Frequency of build verification (QA)
مفهوم: تعداد تولیداتی که یک تیم QA می تواند در یک دوره خاص به مصرف برساند.
دلیل اهمیت: افزایش تعداد تولیداتی که QA می تواند به صورت مثبت مورد مصرف قرار دهد تاثیر مثبتی بر زمانبندی انتشار دارد. ممکن است سرعت استقرار بالا باشد، اما بدون ادغام مستمر (Continuous Integration) باید تولیدات را به صورت دستی مدیریت کنید که این کار باعث کند شدن خط لوله انتشار (DevOps Pipeline) می شود. به طور مشابه، بدون Continuous Testing، حین فرایند تست زمان هدر می رود. نتیجه این است که تیم QA نمی تواند حداکثر تعداد تولیدات را در هر چرخه به مصرف برساند و پوشش تست – همچنین اطمینان از حرکت به مرحله بعد – دچار مشکل است.
ادغام و تست مستمر می تواند فرکانس اعتبار سنجی تولید را افزایش دهد – در بعضی موارد می تواند آن را در هر ماه تقریبا دو برابر کند. وقتی که مقدار این عدد بالا باشد، نشان دهنده پوشش بهتر تست، نشان دهنده ی اطمینان بیشتر برای حرکت به مرحله بعد تولید و سرعت بیشتر تولید است.
 شاخص های کیفیت دواپس | DevOps Quality KPI
شاخص های کیفیت دواپس | DevOps Quality KPI
پیرو مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” که در آن به دلیل اندازه گیری و ارزیابی کیفیت اشاره کردیم، در ادامه به سه تا از شاخص عملکرد کلیدی کیفیت در دواپس می پردازیم.
5. نرخ موفقیت استقرار | Deployment success rate
مفهوم: درصد استقرارهایی که بعد از اعتبار سنجی موفق تلقی شده اند. در اینجا موفقیت به این معنا است که بعد از استقرار، در فاصله ی کوتاهی مجبور به استقرار مجدد یا انتشار patch نشیم.
دلیل اهمیت: نرخ موفقیت بالا هنگام استقرار در سرورهای غیرتولیدی، دلالت بر کیفیت بالا در مراحل قبلی دارد. نرخ موفقیت پایین حاکی از ضعف کیفی کدنویسی است. در خیلی از شرکت ها، ممکن است System Integration Test و QA نرخ موفقیت بالایی داشته باشند ولی در عین حال در محیط پیش عملیات (Staging) موفق نباشند. این معیار می تواند به شما کمک کند تا مشکلات موجود در مرحله استقرار را هدف گرفته و از بین ببرید. نرخ موفقیت باید به مرور زمان افزایش پیدا کند.
در سازمان هایی که عملکرد خیلی خوبی دارند، مقدار این معیار باید به دلیل حذف مشکلات در پیش عملیات (Staging) – یا بهتر از آن، پیشگیری از این مشکلات – بالا باشد. اما خیلی از سازمان ها در این حوزه دچار چالش هستند و باید انتشارها (یا نسخه ها) را به عقب برگردانند. پایین بودن نرخ موفقیت بعد از یک فاز پیمایش موفق می تواند نشان دهنده چندین مشکل باشد:
- فقدان سازگاری بین محیط های مختلف | Lack of consistency across environments
- فقدان مدیریت مناسب داده های تست | Lack of good test data management
- پوشش و کیفیت پایین تست | Low testing quality and coverage
6. میزان حوادث/نقایص | Incident/defect volumes
مفهوم: تعداد حوادث و نقایص گزارش شده در یک نسخه خاص از یک محصول یا سرویس در محیط عملیاتی
دلیل اهمیت: حوادث و نقایص نشان دهنده از دست دادن زمان، پول و فرصت است. بالا بودن عدد این معیار نشان دهنده وجود مشکلاتی در حوزه های زیر است:
- کیفیت نیازمندی ها | Quality of the requirements
- کیفیت توسعه | Quality of development
- کیفیت تست از جمله قابلیت مدیریت داده های تست | Quality of testing, including test data management capability
- سطح همکاری بین استقرار، QA و عملیات (مثلاً اشتباه در درک نیازمندی ها) | Level of collaboration between development, QA, and operations
7. نرخ پوشش نیازمندی ها | Requirements coverage ratio
مفهوم: درصد قابلیت ردیابی (traceability) بین نیازمندی ها و تست ها (منظور امکان ارتباط دادن این دو به هم است).
دلیل اهمیت: عدم سازگاری بین نیازمندی ها و test case منجر به ایجاد مشکل و ضایعات حین چرخه استقرار نرم افزار می شود. وقتی که نیازمندی ها و test case ها به هم ارتباط نداشته باشند، تغییر در نیازمندی ممکن است منجر به شکست test case یا عدم وجود مواردی برای آزمایش شود. test case مشخص نمی کنند که چه تعداد از نیازمندی ها باید تحت پوشش قرار بگیرند و وقتی که تمامی نیازمندی ها را پوشش ندهند، این امر تاثیر منفی مستقیمی بر کیفیت نرم افزار و در نهایت بر تجربیات کاربر خواهد داشت.
وقتی که نیازمندی ها و test case ها با هم هماهنگی داشته باشند، تغییر در نیازمندی ها منجر به قابلیت مشاهده موارد متناظر در پوشش test case می شود. بروز رسانی هر یک از test case به نیازمندی ربط پیدا می کند. وجود ارتباط، تاثیر مثبت و مستقیمی بر کیفیت نرم افزار دارد. بالا بودن میزان این ارتباط نشان دهنده افزایش کیفیت نرم افزار؛ تناقض و ناسازگاری کمتر بین تحلیل گران، توسعه دهندگان و تیم QA؛ و بهره وری بالاتر است.
 شاخص های بهره وری دواپس | DevOps Productivity KPI
شاخص های بهره وری دواپس | DevOps Productivity KPI
گروه دیگر از شاخص هایی که در مطلب قبلی با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” اشاره شد، بهره وری یا Productivity بود. در این خصوص نیز دو شاخص عملکرد کلیدی وجود دارد که شرح خواهیم داد.
8. میزان استفاده از ویژگیها | Feature usage
مفهوم: تعداد یا درصد ویژگی های استفاده نشده از یک محصول یا سرویس خاص وقتی که تولید شده است.
دلیل اهمیت: DevOps یک چرخه بازخوردی است (feedback loop) که شامل بیزنس، توسعه، تست، عملیات و کاربران می شود. پایین بودن میزان استفاده از ویژگیها به این معناست که بخش فناوری اطلاعات (IT) مشغول توسعه ویژگی ها و امکاناتی است که یا مورد تقاضا نیستند (بازخورد ضعیف از سوی بیزنس به بخش توسعه)، یا مورد نیاز نیستند (بازخورد ضعیف از طرف کاربران به بیزنس) یا به صورت ضعیف ساخته شده اند (مشکل در بازخورد از سوی بخش IT). هزینه ویژگی ها و امکاناتی که مورد استفاده قرار نمی گیرند، می تواند بسیار زیاد باشد، بنابراین مهم است که علت این امر شناسایی شود. بالا بودن تعداد ویژگی هایی که در یک محصول خاص استفاده نشده اند نشان دهنده منفی بودن میزان اثربخشی مدیریت و توسعه نیازمندی ها است.
9. میانگین زمان لازم برای بازیابی سرویس | Mean time to restore service (MTTRS)
مفهوم: زمان بازیابی یک سرویس یا عملکرد، وقتی که در اثر وجود نقصی که نیاز به اصلاح یا توسعه دارد، اختلالی بوجود آمده باشد. به بیان دیگر وقتی که خطایی پیدا می شود، چقدر طول می کشد که آن خطا اصلاح شده و محصول عرضه شود؟
دلیل اهمیت: اگر اپلیکیشنی با تمام ویژگی ها و عملکردهای مورد نیاز منتشر کنید، ولی مشخص شود که این اپلیکیشن قابل اطمینان نیست یا بازیابی آن بعد از شکست زمان زیادی می برد، این امر باعث می شود تمام ارزش های ایجاد شده توسط تولید ویژگی ها و توابع مناسب در مراحل قبل از بین برود. مسلما نمی توان از هر نوع شکستی پیشگیری کرد اما می توان انعطاف پذیری اپلیکیشن ها و نحوه پاسخگویی تیم را بهبود بخشید. هر دقیقه از کار افتادگی یک سرویس، باعث از دست دادن درآمد، مشتری ها و کیفیت برند می شود.
بعلاوه، MTTRS می تواند مشخص کننده مشکلاتی در سازمان باشد از جمله:
- وضعیت سلامت چرخه بازخورد بین بیزنس، بخش های توسعه، QA، عملیات و کاربران نهایی.
- سطح چابکی شرکت و این که شرکت با چه سرعتی می تواند به تغییرات ایجاد شده توسط یک فرد، فرایند و تکنولوژیهای آینده واکنش نشان دهد.
- بهره وری و اثربخشی کلی
- The health of the feedback loop between the business, development, QA, operations, and end users
- The level of enterprise agility and how quickly the enterprise can react to changes from a people, process, and technology perspective
- Overall productivity and effectiveness
 شاخص های امنیت دواپس | DevOps Security KPI
شاخص های امنیت دواپس | DevOps Security KPI
سرعت، کیفیت و بهره وری بدون امنیت می تواند کل سرویس را به خطر بیاندازد. در مطلب قبل با عنوان “ارزیابی میزان موفقیت عملکرد دواپس با شاخص های عملکرد کلیدی” به اهمیت اندازه گیری امنیت در دواپس اشاره کردیم و در ادامه دو تا از KPI های مهم در این خصوص را شرح خواهیم داد.
10. میزان قبول شدن تست امنیت | Security test pass rate
مفهوم: نسبت شکست در مقایسه با موفقیت در گذراندن اسکن امنیتی کدهای بعد از بیلد کردن محصول در یک دوره زمانی خاص.
دلیل اهمیت: مشخص شدن آسیب پذیری های امنیتی در مرحله تولید، به این موضوع را تضمین می کند که همیشه قبل ورود به سایر بخش های DevOps Pipeline، محصولاتی سبز و خوب تولید می شوند.
11. نرخ تشخیص اسکن کدها | Code scanning detection rate
مفهوم: تعداد اسکن های امنیتی که در یک بازه زمانی یا فاز پردازش خاص، مشکلی را مشخص می کنند همراه تعداد مشکلات.
دلیل اهمیت: این نرخ باید با گذشت زمان یا با حرکت از مرحله ای به مرحله بعد در خط لوله کاهش پیدا کند. اگر نرخ موفقیت اسکن امنیتی رو به بهبود باشد، این اطمینان ایجاد می شود که سرعت توسعه و انتشار ویژگی های جدید طوری است که بجای آسیب رساندن به امنیت، باعث پایداری محصول می شود.

تحلیل مناسب اعداد و ارقام
DevOps این قابلیت را دارد که زنجیره ارائه نرم افزار را به ماشینی با تفکر ناب، سریع و به شدت موثر تبدیل کند تا آنچه کاربران تقاضا دارند را عرضه کند. این تبدیل اهمیت بسیار زیادی دارد. طبق یکی از نظر سنجی های شرکت Forrester Consulting که در سال 2015 انجام شده، 64 درصد از پاسخ دهندگان بر این باورند که نرم افزار یکی از عوامل کلیدی توانمندساز مشاغل است و موفقیت مشاغل بستگی به اپلیکیشن هایی با کیفیت بالا دارد که مناسب با مدل های بیزنسی مدرن باشد.
DevOps has the potential to transform the software delivery chain into a lean, fast, highly effective machine that delivers what users want.
شرکت نرم افزاری HPE با کمک داده های حجیم معیارهایی را از منابع مختلف در سیستم های IT مختلف جمع آوری کرده است تا این 11 شاخص کلیدی عملکرد و موارد دیگر را تولید کند. ابتکار شرکت نرم افزاری HPE دیدگاهی واحد از معیارهای DevOps فراهم می کند که به شما برای بدست آوردن اطلاعات و بینش هایی درباره مسیر حرکت DevOps کمک می کند؛ به طوری که می توانید به شیوه ای موثر و کارآمد تبدیل و تحول DevOps را مدیریت کنید.
مسیرهای آتی برای شاخص های کلیدی عملکرد DevOps
وقتی که شروع به استفاده از شاخص های کلیدی عملکرد برای ارزیابی موفقیت DevOps کردید، راه های زیادی برای گسترش داشبورد معیارهای دواپس و متناسب کردن آن با سایر سطوح سازمان خواهید داشت. برای گسترش معیارهای DevOps به سمت بالا و حوزه بیزنس، داشبورد KPIی DevOps را می توان به صورت یک داشبورد مخصوص مدیر ارشد فناوری اطلاعات درآورد که دیدگاهی سطح بالا از تشکیلات IT و همچنین میزان پیشرفت در فعالیت های عمده فراهم کند. (DevOps Dashboard)
یکی از شاخص های کلیدی عملکرد که در حال حاضر مشاغل علاقه زیادی به آن دارند، میزان استفاده از ویژگی ها است اما می توانید در کنار آن، زمان چرخه را هم نظارت کنید که نشان می دهد تولید یک ویژگی خواسته شده و استقرار آن در یک محصول چقدر زمان می برد. البته شاخص های کلیدی عملکرد از نوعِ اقتصادی نیز همیشه برای مشاغل متناسب و مهم هستند – که یکی دیگر از راه های گسترش داشبورد را تشکیل می دهند.
بعلاوه می توانید داشبورد DevOps را به سمت پایین هم گسترش دهید تا فعالیت های روزمرهی افراد را تحت پوشش قرار دهد.
استفاده از معیارها برای ادامه مسیر حرکت DevOps
DevOps یک سفر و یک سیر تکاملی است نه یک پیاده سازی یک شبه. هر چند خیلی از ابتکارات با برداشتن قدم های کوچک شروع می شوند، اما DevOps نیاز به تعهد به یک نوع فرهنگ جدید دارد. به همین خاطر است که شرکت هایی که امروزه به دنبال پیاده سازی دواپس هستند، احتمالا نیاز به تحویل طرح فعالیت تجاری جدید به مدیران سازمان دارند. سازمان های دیگری که از قبل دواپس را آزمایش و تجربه کرده اند، ممکن است آماده باشند که اطلاع را جمع آوری و رویکردشان را بهینه سازی کنند. در هر صورت وجود معیارهای قابل رویت و مفید در موفقیت DevOps تاثیر بسیار زیادی دارد.
“تشکیلات IT باید این امر را به رسمیت بشناسند که DevOps قابلیت تحول و تغییر را دارد و بر این اساس باید در جنبه های فردی و فرایندی تلاش هایشان سرمایه گذاری زمانی و پولی کنند. مدیران IT نباید بیش از حد بر فناوری تاکید کنند و در نتیجه حوزه های دیگر را تحت تاثیرات منفی قرار دهند.”
منبع : “Hewlett Packard Enterprise, “Measuring DevOps success